
先上笔试题

算法题没啥难度,简单写一下
二叉树有三种遍历方式
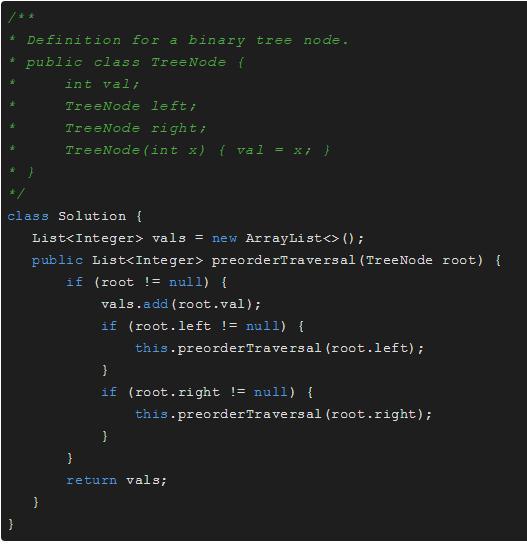
前序遍历:根,左,右
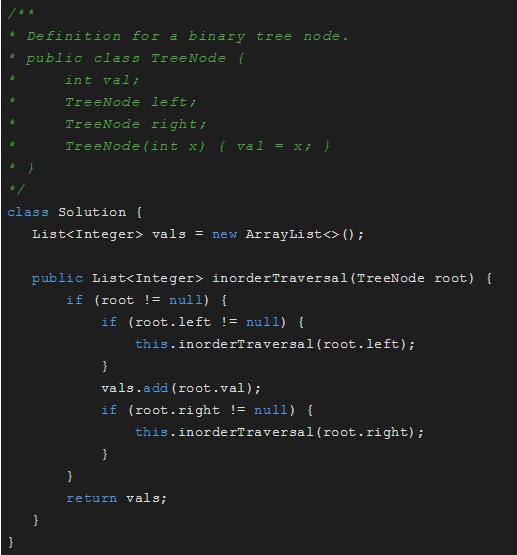
中序遍历:左,根,右
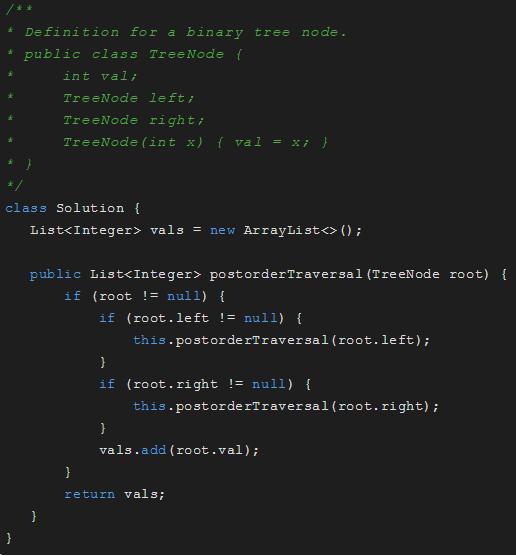
后序遍历:左,右,根
发现规律没?左右的位置始终不变,前序遍历,根在前面,中序遍历,根在中间,以此类推。

前序遍历:A B C D E F
中序遍历:C B D A E F
后序遍历:C D B F E A
前序遍历
中序遍历
后序遍历
常用Linux命令
简单说几个,ls mkdir 面试就不用写了,简单的命令大家都会,top,free之类的写写
less — print LESS
less 按页或按窗口打印文件内容。在查看包含大量文本数据的大文件时是非常有用和高效的。你可以使用Ctrl+F向前翻页,Ctrl+B向后翻页。
ping
ping 通过发送数据包ping远程主机(服务器),常用与检测网络连接和服务器状态。
如 ping www.baidu.com
su — Switch User
su 用于切换不同的用户。即使没有使用密码,超级用户也能切换到其它用户。
top — Top processes
top命令会默认按照CPU的占用情况,显示占用量较大的进程,可以使用top -u 查看某个用户的CPU使用排名情况。
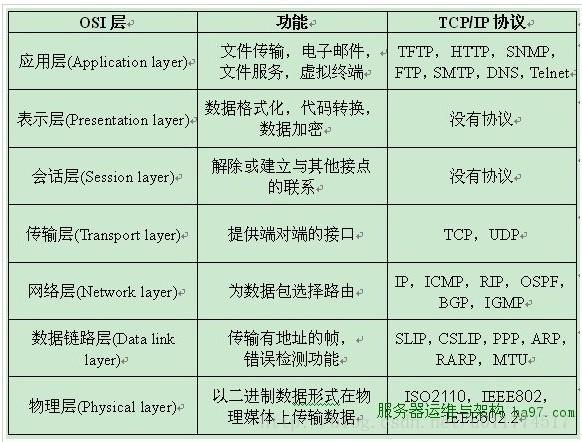
OSI七层模型
http请求方式与区别
(1)对参数的数据类型,GET只接受ASCII字符,而POST没有限制,允许二进制。
(2)GET在浏览器回退/刷新时是无害的,而POST会再次提交请求。
(3)GET请求只能进行url编码(application/x-www-form-urlencoded),而POST支持多种编码方式(application/x-www-form-urlencoded 或 multipart/form-data),可以为二进制使用多重编码。
(4)POST 比 GET 更安全,因为GET参数直接暴露在URL上,POST参数在HTTP消息主体中,而且不会被保存在浏览器历史或 web 服务器日志中。
(5)对参数数据长度的限制,GET方法URL的长度是受限制的,最大是2048个字符,POST参数数据是没有限制的。
(6)GET请求会被浏览器主动缓存,POST不会,除非手动设置。
(7)GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
(8)GET请求可被收藏为书签,POST不能。
http常见的状态码
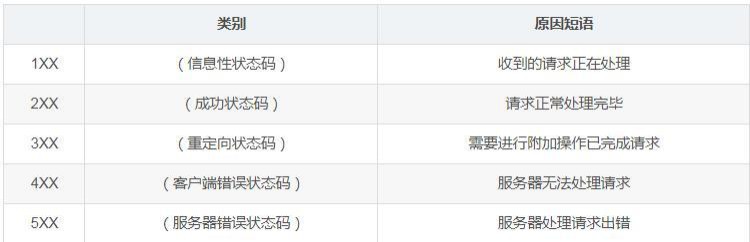
我单写一篇文章来描述http状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
访问网页的过程,越详细越好
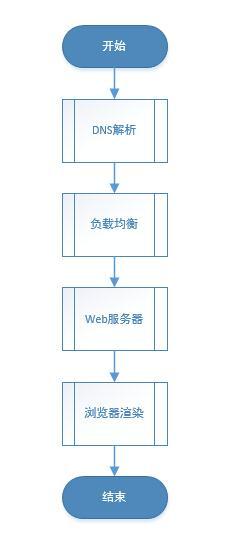
详细过程单开一篇文章
一面-反向打印链表的值
如链表的值为1-2-3-4,打印出的值为4 3 2 1
将值放在数组中,然后反向遍历数据输出,这种方法不太优雅
正确的方式如下,一个递归搞定
public Class Node {
int value;
Node next;
}
public static void printNode(Node node) {
if (node == null) return;
printNode(node.next);
Systme.out.println(node.val);
}
一面-主键用自增id好,还是uid好?
当然是自增id了,自主键的数据结构是B+树,用自增id不会造成树的分裂,uid不规则,会造成树的分裂,效率比较低
二面
给一个数组有n个值,求m个值和为24的所有组合
回溯,DFS,算法均可,不写代码了,知道思路即可
数据单向链表中倒数第n个节点的值
我刚开始是,遍历一遍链表,求出长度,然后再遍历一变到n-k,结果告知这种方法效率比较低
后来想到,用2个指针,中间相隔n个距离,当一个指针到了尾节点时,另一个节点正好指向倒数第n个节点
其他就是类似一些string,stirngbuffer,stringbuild的区别
nio和bio的区别
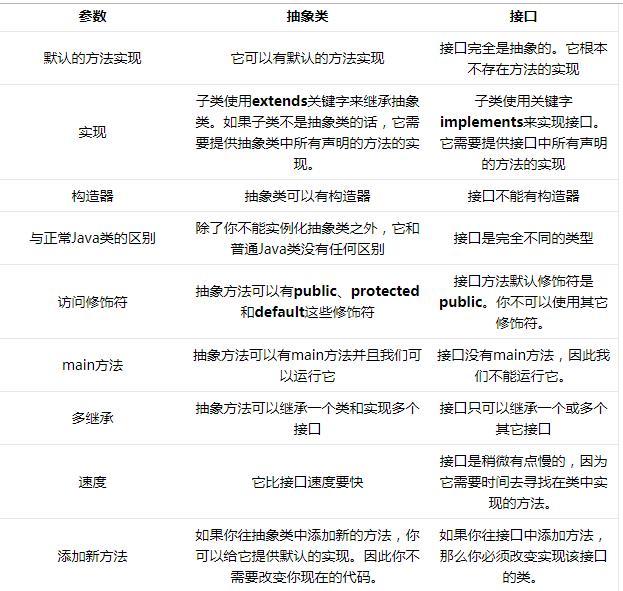
抽象类和接口的区别
关注Java识堂,持续分享北京几十家公司面试真题,有好的面试题也可能分享给我,欢迎进群
764113208 交流面试过程,欢迎加我微信zztierlie