简介: 随着云原生技术的不断发展,数据库也逐渐进入了云原生时代。在云原生时代,如何高效、安全且稳定地管理云上与云下的数据库成为摆在企业面前的一大难题。在第十一届中国数据库技术大会(DTCC2020)上,阿里巴巴数据库生态工具团队高级技术专家程实(花名:时勤)就为了大家分享了云原生时代的数据库管理体系以及解决方案。


本文内容根据演讲录音以及PPT整理而成。
本次分享将为大家介绍如何组合使用阿里巴巴云原生数据库管理体系产品为用户打造完整的解决方案。
云原生的数据库管理体系
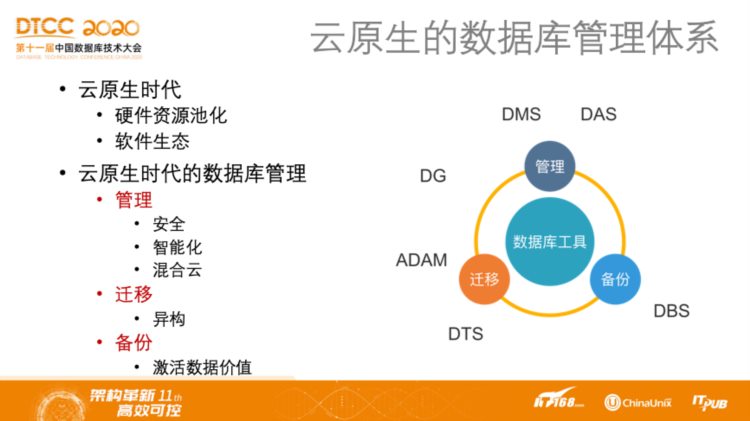
云原生时代的主要特征可以大致归纳为两点,即硬件特征和软件特征,前者指的是硬件资源池化所带来的高可用和弹性等;后者指的是在云原生时代,很多工具无需企业自己研发,而可以通过API的方式调用软件功能的组合,进而有机地组合成软件生态。
那么,云原生时代的数据库管理需要哪些技术呢?其实可以主要分为三类,即管理、迁移和备份。其中,管理需要安全、智能化以及面向混合云的能力;迁移主要面对的挑战在于数据库的异构;而对于备份而言,如今需要解决的并不是能否备份成功,而是如何激活数据价值。
阿里云数据库工具体系
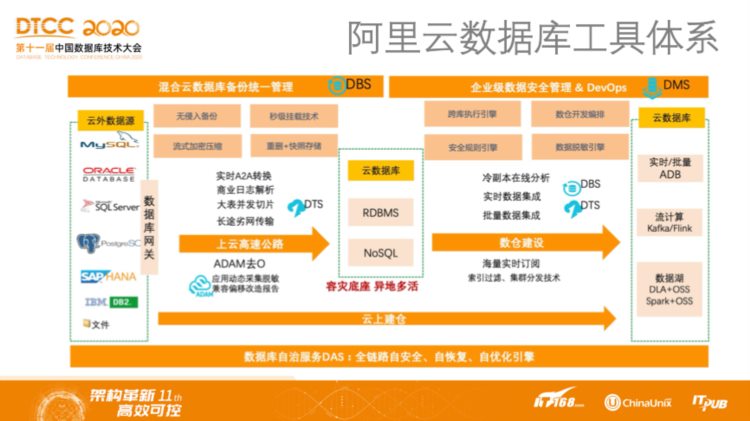
如上图所示的是阿里云数据库工具体系。从图中可以看到,首先,通过DBS、DTS数据迁移、数据库备份这样的工具可以打通从其他云或者云下到阿里云上的数据库,并且还可以使得阿里云上的数据库与阿里云上的计算平台、流计算平台以及数据分析平台之间实现打通。其次,通过DMS这样的数据库管理服务可以管理云上和云下的计算型和分析型数据库。再次,阿里云还提供了数据库自治服务DAS,也就是用于优化数据库管理相关服务的智能化自治平台。
非云数据库如何拥抱云原生?——云原生赋能

接下来分析一个用户常见的问题,就是对于用户而言,如果其已有的大量数据库是非云数据库实例,应该如何拥抱云原生技术?我们当然可以为其介绍一款云原生数据库产品,但是用户所想要了解的其实是如何使用这款产品,如何将数据迁移过来,以及线下的数据库实例如何与云原生数据库共同发挥作用。也就是说,对于用户而言,实际上需要的是一套解决方案。
阿里云数据库为用户提供了三种解决方案,可以适用于用户不同的场景。
接下来介绍一些阿里云所提供的数据库工具。
DMS数据管理——权限管理最佳实践

在DMS数据管理产品中存在“三权分立”的概念,这种概念也是数据库管理在大型企业中的一个最佳实践。这里大致介绍一下,首先要有管理员或超级管理员的角色,通常由运维Leader或者CTO担任,其主要负责定义人员的角色和分配人员的权限。其次,通常要有DBA或者运维人员,其负责数据库的实际操作运维,比如扩容、Schema的变更等。最后的也是现在比较关注的,叫做安全管理员,其负责制定数据操作规范,比如每天可以操作多少次,在什么样的窗口可以完成这个操作,以及一次操作的范围有多大等。安全管理员一方面约束DBA,另外一方面则约束第四种角色,即普通用户,比如业务方的用户只需要读写某个数据库,而并不需要操作数据库实例,则需要受到安全管理员的约束;再比如有些高风险业务或者高敏感业务,业务人员不希望运维人员看到具体数据,特别是对于云服务而言,因此也需要受到安全管理员的约束。安全管理员在DMS上可以约束每个类型的普通用户,他可以看到甚至约束DBA所能够看到的数据,还可以定义数据的脱敏处理,实现行级别的数据查询约束。
DMS数据管理——与企业内部账号SSO系统打通
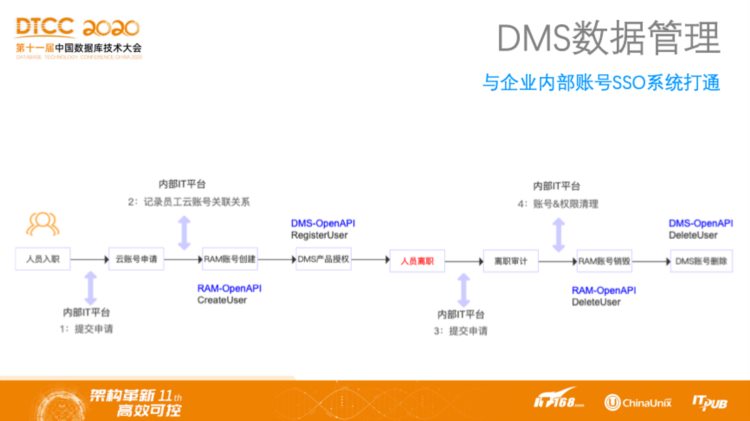
上述数据管理最佳实践落地的最大阻碍在于人和权限的管理没有到位。对于公司而言,必然存在人员的入职、离职、以及部门更换等流动性过程,因此一定要实现人员权限与其当前位置的强关联,这样才是有效的管理,否则权限体系就会崩塌掉。DMS通过提供OpenAPI体系可以支持与企业的单点登录系统SSO,也就是企业的权限管理系统进行对接。无论是员工入职、更换部门还是岗位、职位调整,都可以通过在系统中联动DMS的OpenAPI完成权限改变,使得员工权限始终与其岗位和部门保持一致。
DMS数据管理——变更安全/研发效能

阿里云DMS所提供的功能还有很多,比如研发效能方面的变更工单系统、跨库查询等,变更安全方面的SQL审核、数据脱敏、日志追踪和回滚以及不锁表变更等。其中,DMS在数据脱敏方面能够提供智能分析的能力,即便不告诉DMS哪些数据属于敏感数据,其也能够智能分析出来;在日志追踪与回滚方面,DMS能够从日志中分析出某行数据记录历史的修改情况,而不仅仅是展现最终的数据修改结果,并且能够帮助用户自动生成回滚SQL。在不锁表变更方面,相当于把用户提交的Schema或者批量的DML变更变成数据拷贝之后,在拷贝的副本上面进行变更,然后再完成替换操作。
DAS数据库自治——自动优化参数
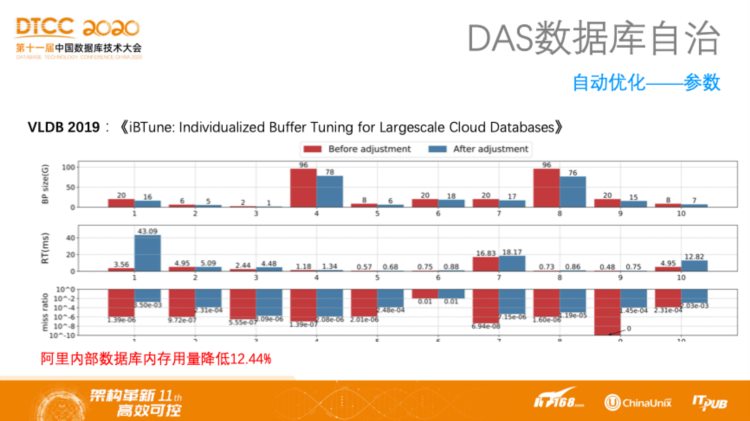
DAS是一款数据库自治产品,这里重点介绍DAS在去年和今年发表的两篇VLDB论文。在2019年发表了题为《iBTune: Individualized Buffer Tuning for Largescale Cloud Databases》的论文,主要是利用机器学习技术智能地调整缓存大小。当DBA只管理10个以内的数据库,可以用大脑进行记忆像每个数据库所需要的缓存大小、缓存命中率以及业务RT要求等信息,而对于像阿里巴巴这样的情况,需要少量的DBA应对上万的数据库。此外。在用户并不具备数据库调优知识时,人工调整缓存也非常困难。上面这篇论文就尝试解决这样的问题,它通过机器学习方法,预测将缓存降低到什么情况,缓存命中率和RT的值会发生什么变化,其中使用的是深度神经网络技术。这样的预测技术在阿里巴巴内部上万个数据库实例中使用得到的收益就是使得数据库内存用量降低了12.44%。
DAS数据库自治——自动优化SQL
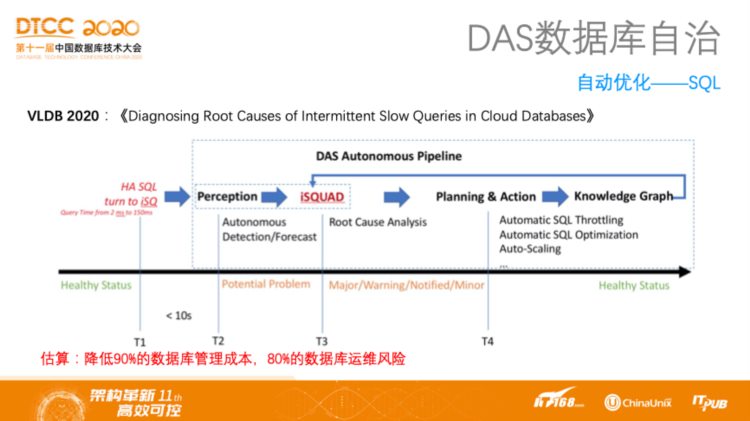
上图展示的是阿里巴巴DAS在今年VLDB上发布的题为《Diagnosing Root Causes of Intermittent Slow Queries in Cloud Databases》 的论文,主要做的事情就是智能分析慢查询,分析后的操作分别是自动对SQL进行限流、自动对SQL进行优化以及自动扩容。这样的事情可能看上去是DBA拍脑袋能决定的事情,但是当面对成千上百个数据库的时候,想要了解每个数据库有哪些SQL,以及哪些SQL造成了哪些问题都是非常困难的,是人力无法做到的,一定需要借助机器学习的方法。
DAS数据库自治——自修复、自安全、自运维
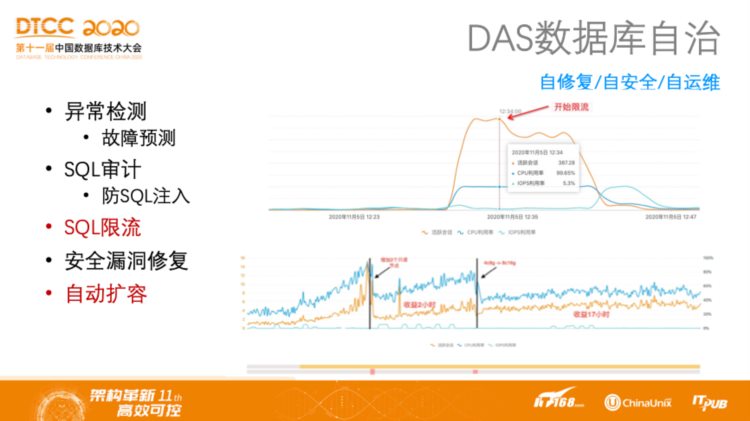
对于数据库自治而言,什么时候限流、什么时候扩容,这两个场景其实是不一样的。如果通过原有的流量预测,熬过了这段时间流量就会下来,那么此时不应该扩容,因为这是一个短暂的峰值流量,为了短暂突发的峰值流量而扩容是不合适的,那么此时可以对它进行限流。但是如果流量持续上涨,并且预测未来流量还会越来越高,那么就应该扩容。DAS可以自动化地完成预测,无需DBA人工决策。此外,DAS还提供了异常检测、故障检测、SQL审计、防注入、安全漏洞修复等一系列功能,详情可以参考DAS官方文档。
DG数据库网关——打通私网、本地IDC和他云
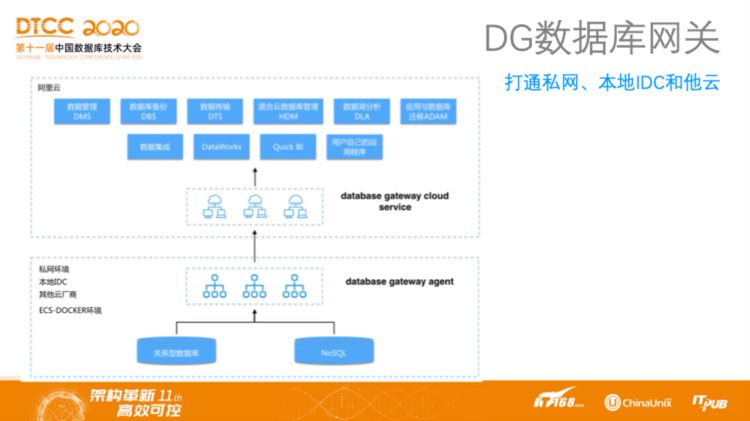
DG的主要作用是打通线上云数据库和线下,前面提到一种方案是管理在线上,用户数据在线下,用户很容易觉得不安全,可能认为需要在线下开放一个数据库的公网端口来便于管理。但是阿里云提供的方案并不是这样的,不用暴露任何的对外的端口,通过反向建立TCP通道的方式,把DG的一端连接到线下数据库,另一端连到线上管理服务,比如DMS和DAS服务来完成对数据库的管理,而它的通道是加密的。
DTS数据传输——整体架构
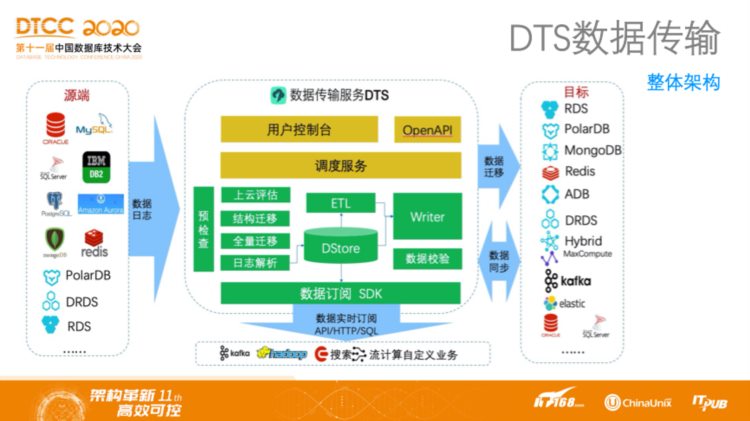
其实,阿里巴巴是最早做数据传输服务的,在阿里云诞生之前,DTS的前身DRC就是在阿里内部做数据传输的,而阿里早期引以为傲的技术,比如异地多活等都是靠点对点数据同步完成的。现在的DTS作为云服务,其核心竞争力就是支持非常多的源库和目的库类型,而这一点的实现并不简单,因为不同数据库的日志结构和分布式架构都不一样,想要支持这些数据库往往需要经过大量的探索,因此在技术上有相当高的门槛。此外,DTS除了支持从数据库向数据库进行迁移之外,还支持向一些分析平台进行迁移,或通过订阅方式向一些流计算平台进行迁移,订阅接口也兼容Kafka的SDK。
DTS数据传输——核心技术:事务级实时同步
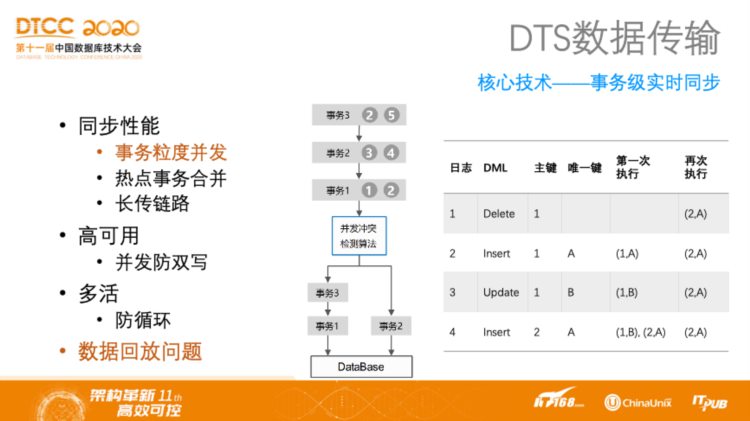
DTS具有事务级别并发的同步。阿里云DTS其实是最早开始研究事务级实时同步的,甚至比MySQL官方更早。此外,在高可用情况下需要防止双写,在多活状态下需要防止循环,并且需要应对数据回放时可能会产生错误的问题。
ADMA专业迁移——整体流程

ADAM是一个专家的数据迁移服务,之所以在前面加了“专家”这样的形容词,是因为其不仅仅是对数据进行异构迁移和解决数据在两端的存储问题,更多的是帮助用户进行数据库选型。ADAM会尝试去分析用户线下使用的数据库,比如ADAM可以帮助用户分析使用的SQL、存储过程等,可以分析出线上某个数据库是否支持这些,如果不支持又可以使用其他什么方案,这也是数据库架构师或者DBA需要解决的问题,而目标数据库的选型在ADAM中得到了很好的解决。其次,ADAM能够实现兼容性分析和自动SQL改造,这是因为数据库与数据库之间,即使是写入的SQL也是不同的,更何况还有查询的SQL和Join查询等,虽然都遵循SQL 99规范,但是都有各自方言的SQL语法。最后是自动数据订正,甚至可以指导应用来修改应用配置和参数来适配新的数据库,因此叫做专家服务。ADAM即将要推出数据迁移实验室,用户将可以在不真正动数据的情况下进行数据迁移尝试,以此分析SQL以及数据库管理有何不同。
ADAM——核心技术:SQL语法转换
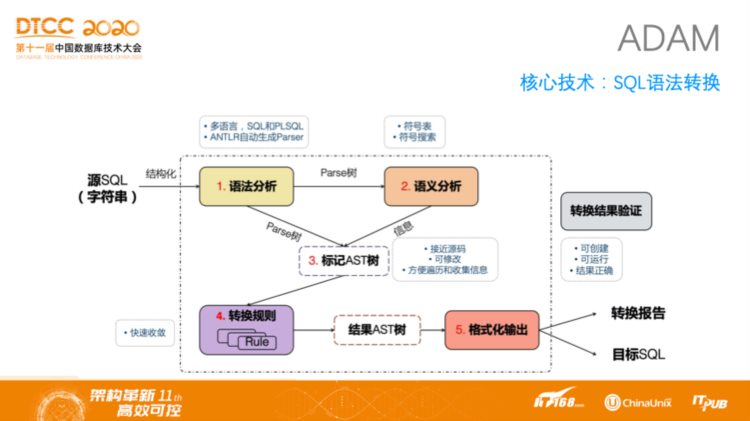
上图展示的是ADAM关于SQL语法转换的技术示意图。ADAM将源SQL通过标记AST语法树的方式转化成目标SQL,并针对于转换中出现的问题输出转换报告。
DBS数据库备份——整体架构
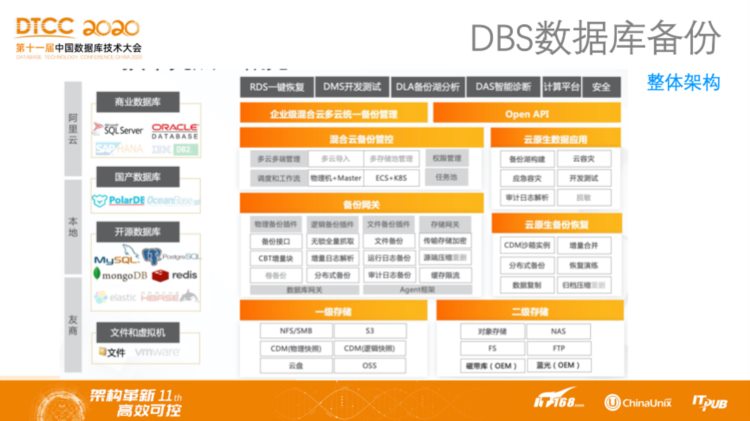
DBS数据库备份是阿里云目前正在重点研发的产品,上图展示了其技术整体架构。
DBS数据库备份——核心技术:物理全量PIT拷贝、物理增量CBT
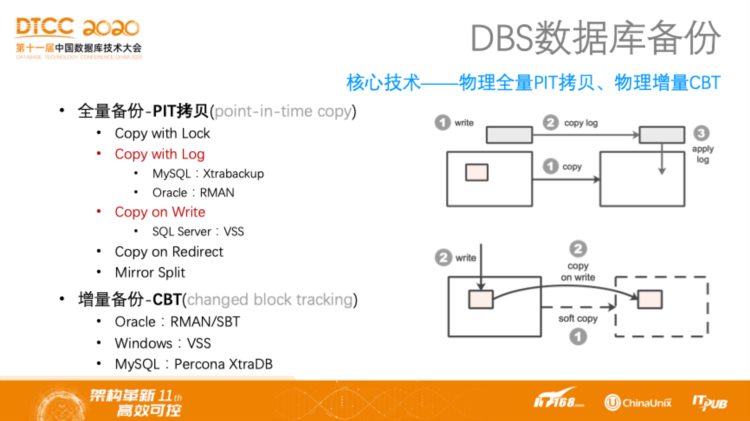
简单分享一下DBS备份所使用的核心技术,首先是物理备份技术,也就是让用户在无感知的情况下高速完成数据备份。目前,业界在物理备份主要需要面对两个主要技术问题,一个是全量备份的PIT拷贝(Point-in-time Copy)问题,面对这一问题业界提出了五种技术方案,即Copy with Lock、Copy with Log、Copy on Write、Copy on Redirect和Mirror Split。Copy with Lock方案最为简单,就是加一把锁,比如拷贝MySQL数据库,可以将其全部锁住,并将文件拷贝出来,这样拷贝出来的文件一定是一致的。所谓Copy with Log就是边拷贝数据边拷贝日志,之后将这段时间拷贝的日志进行回放,MySQL使用Xtrabackup,而Oracle使用RMAN,也都是基于这种方案。而SQL Server数据库所依赖的VSS机制就是使用的Copy on Write方案,可以没有日志,而是在业务和存储层接口部分有一层约定来实现一致性拷贝。Mirror Split方案主要用于专用设备。第二个问题就是增量备份CBT(Changed Block Tracking),在增量备份时需要发掘哪些数据块从上一次到这一次是被修改过的,这样的发掘能力对于不同的数据库而言,所使用的技术也是不一样的,比如Oracle使用RMAN和SBT。Windows使用VSS,而MySQL方面,官方的Percona的XtraDB提供了CBT功能,对于不是这样的MySQL,则必须要通过扫描方式将更改的数据块找出来,因此在使用Xtrabackup备份数据的时候开销很大,而阿里云DBS在这些方面做了大量的优化工作。
DBS数据库备份——核心技术:数据湖分析
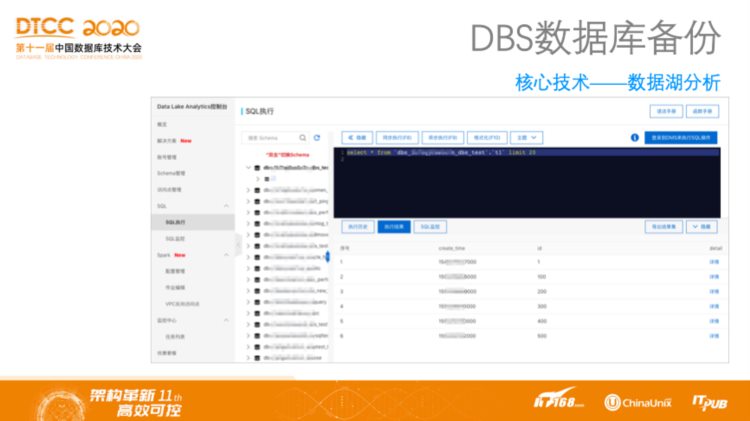
前面提到希望将二级数据放在云上并发挥数据价值,上图所示的是将数据备份到对象存储之后,直接建一个数据湖,然后实现对于数据提交SQL查询的分析,这意味着数据并不需要再恢复到某个数据库了,可以直接对备份数据进行SQL查询,这对用户是非常友好的,比如对于历史数据的查询只需要在备份数据上就可以完成。
DBS数据库备份——核心技术:CDM沙箱
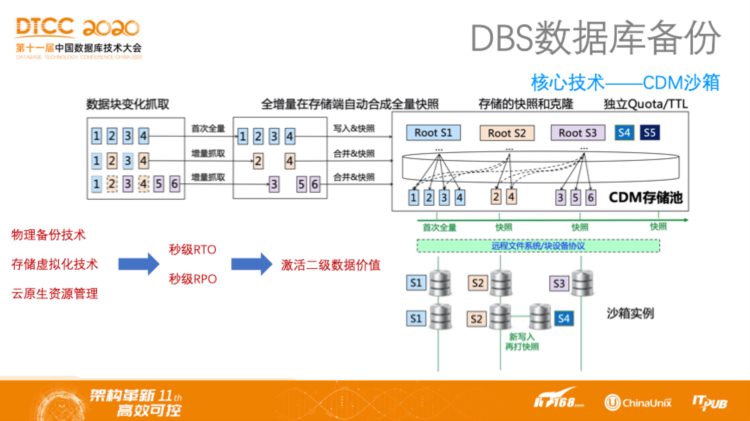
前面所提到的方案实际上会涉及到对象存储接口的多次调用,因此其性能不如原生数据库,但阿里云提供了更好的方案。如果做物理备份,那么可以运用物理备份技术加存储虚拟化技术,再加上云原生技术,帮助用户直接在线上以秒级速度创建一个新的实例,而且创建的数量没有限制。这项技术在业界叫做Copy Data Management,最近在数据备份的专业领域比较流行。而阿里云能够实现在任何一个时间点都可以秒级速度拉起一个新的沙箱实例,该实例可以作为应急容灾对象,也可以用于做开发测试。
最后针对前面所提到的三个问题给出相应的解决方案。
解决方案1:DTS+ADAM——整体迁移上云
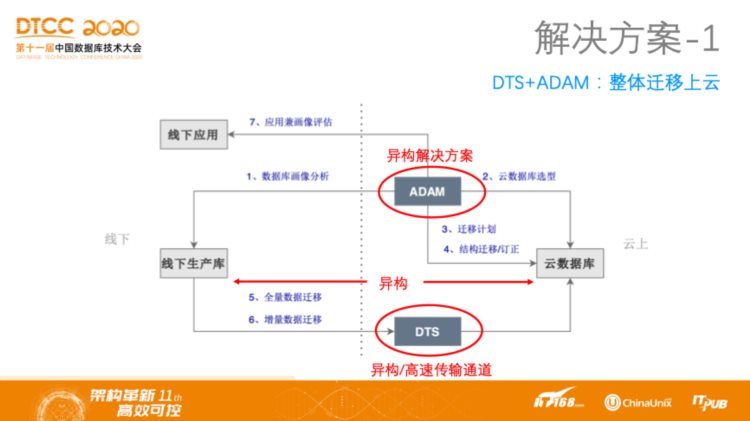
第一种方案是整体上云,阿里云给出的就是ADAM+DTS的技术组合方案。ADAM完成数据库画像分析和云数据库选型,生成迁移计划并进行结构的迁移和订正,DTS对于数据进行全量和增量的迁移,最后ADAM还要对于线下应用进行画像评估。第一个方案所需要解决的最主要问题就是数据库异构问题,并打通异构通道。
解决方案2:DMS+DAS+DG——云下数据+云上管理
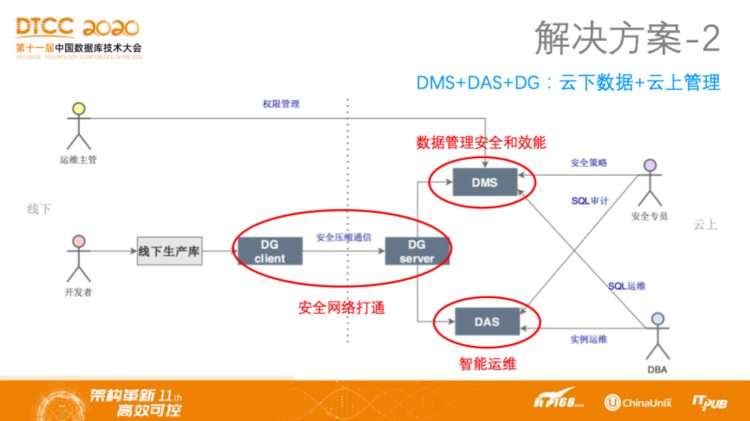
第二种解决方案是针对云下数据、云上管理的情况,首先通过DG实现安全网络打通,然后通过DMS管理线下的数据库并通过DAS智能运维线下数据库。而不同身份的数据库使用者面向不同平台来使用不同的数据服务。
解决方案3:DBS+DMS+DAS:云下生产数据+云上二级数据
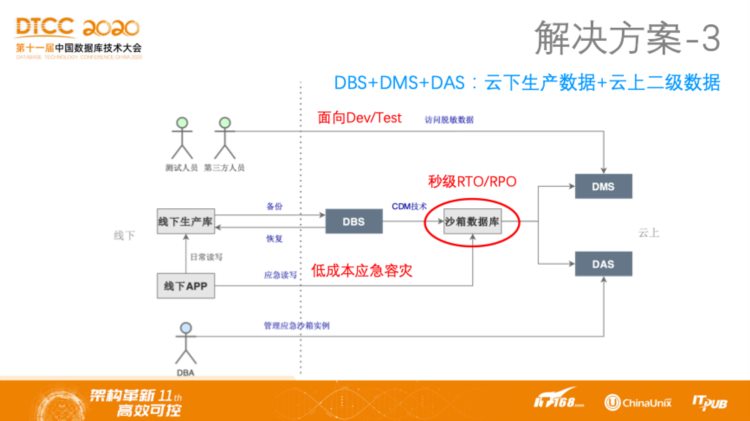
第三种方案是云下生产数据+云上二级数据,首先通过DBS将数据备份到云上,通过CDM技术生成沙箱实例,既可以满足应急读写需求,也可以面向开发测试秒级提供数据库副本,并且可以通过DAS实现对于数据库沙箱实例的运维管理。
作者:stromal
本文为阿里云原创内容,未经允许不得转载