导读:笔者早年间从事了多年开发工作,后因个人兴趣转做数据库。在长期的工作实践中,看到了数据库工作(特别是SQL优化)面临的种种问题。本文通过几个案例探讨一下SQL优化的相关问题。
作者:马立和 高振娇 韩锋
来源:华章科技

案例01 一条SQL引发的“血案”
1. 案例说明
某大型电商公司数据仓库系统,正常情况下每天0~9点会执行大量作业,生成前一天的业务报表,供管理层分析使用。但某天早晨6点开始,监控人员就频繁收到业务报警,大批业务报表突然出现大面积延迟。原本8点前就应跑出的报表,一直持续到10点仍然没有结果。公司领导非常重视,严令在11点前必须解决问题。
DBA紧急介入处理,通过TOP命令查看到某个进程占用了大量资源,杀掉后不久还会再次出现。经与开发人员沟通,这是由于调度机制所致,非正常结束的作业会反复执行。
暂时设置该作业无效,并从脚本中排查可疑SQL。同时对比从线上收集的ASH/AWR报告,最终定位到某条SQL比较可疑。
经与开发人员确认系一新增功能,因上线紧急,只做了简单的功能测试。正是因为这一条SQL,导致整个系统运行缓慢,大量作业受到影响,修改SQL后系统恢复正常。
- 具体分析
SELECT/*+INDEX(A1xxxxx)*/SUM(A2.CRKSL),SUM(A2.CRKSL*A2.DJ)...
FROMxxxxA2,xxxxA1
WHEREA2.CRKFLAG=xxxANDA2.CDATE>=xxxANDA2.CDATE<xxx;这是一个很典型的两表关联语句,两张表的数据量都较大。下面来看看执行计划,如图1-1所示。
执行计划触目惊心,优化器评估返回的数据量为3505T条记录,计划返回量127P字节,总成本9890G,返回时间999:59:59。
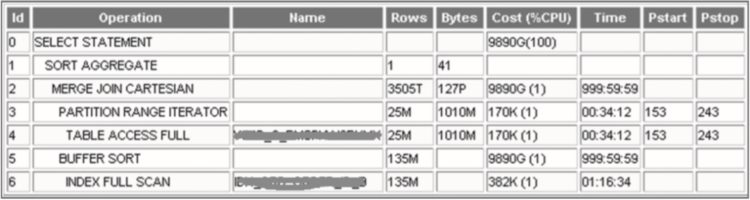
▲图1-1 执行计划
- 分析结论
从执行计划中可见,两表关联使用了笛卡儿积的关联方式。我们知道笛卡儿连接是指两表没有任何条件限制的连接查询。一般情况下应尽量避免笛卡儿积,除非某些特殊场合,否则再强大的数据库也无法处理。
这是一个典型的多表关联缺乏连接条件,导致笛卡儿积,引发性能问题的案例。
2. 给我们的启示
从案例本身来讲并没有什么特别之处,不过是开发人员疏忽导致了一条质量很差的SQL。但从更深层次来讲,这个案例可以给我们带来如下启示。
- 开发人员的一个疏忽造成了严重的后果,原来数据库竟是如此的脆弱。需要对数据库保持“敬畏”之心。
- 电脑不是人脑,它不知道你的需求是什么,只能根据写好的逻辑进行处理。
- 不要去责怪开发人员,谁都会犯错误,关键是如何从制度上保证不再发生类似的问题。
3. 解决之道
1)SQL开发规范
加强对数据库开发人员的培训工作,提高其对数据库的理解能力和SQL开发水平。将部分SQL运行检查的职责前置,在开发阶段就能规避很多问题。要向开发人员灌输SQL优化的思想,在工作中逐步积累,这样才能提高公司整体开发质量,也可以避免很多低级错误。
2)SQL Review制度
对于SQL Review,怎么强调都不过分。从业内来看,很多公司也都在自己的开发流程中纳入了这个环节,甚至列入考评范围,对其重视程度可见一斑。其常见典型做法是利用SQL分析引擎(商用或自研)进行分析或采取半人工的方式进行审核。审核后的结果可作为持续改进的依据。
SQL Review的中间结果可以保留,作为系统上线后的对比分析依据,进而可将SQL的审核、优化、管理等功能集成起来,完成对SQL整个生命周期的管理。
3)限流/资源控制
有些数据库提供了丰富的资源限制功能,可以从多个维度限制会话对资源(CPU、MEMORY、IO)的使用,可避免发生单个会话影响整个数据库的运行状态。
对于一些开源数据库,部分技术实力较强的公司还通过对内核的修改实现了限流功能,控制资源消耗较多的SQL运行数量,从而避免拖慢数据库的整体运行。

案例02 糟糕的结构设计带来的问题
1. 案例说明
这是某公司后台的ERP系统,系统已经上线运行了10多年。随着时间的推移,累积的数据量越来越大。随着公司业务量的不断增加,数据库系统运行缓慢的问题日益凸显。
为提高运行效率,公司计划有针对性地对部分大表进行数据清理。在DBA对某个大表进行清理时出现了问题。这个表本身有数百吉字节,按照指定的清理规则只需要根据主键字段范围(运算符为>=)选择出一定比例(不超过10%)的数据进行清理即可。
但在实际使用中发现,该SQL是全表扫描,执行时间大大超出预期。DBA尝试使用强制指定索引方式清理数据,依然无效,整个SQL语句的执行效率达不到要求。为了避免影响正常业务运行,不得不将此次清理工作放在半夜进行,还需要协调库房等诸多单位进行配合,严重影响正常业务运行。
为了尽量减少对业务的影响,DBA求助笔者帮助协同分析。这套ERP系统是由第三方公司开发的,历史很久远,相关的数据字典等信息都已经找不到了,只能从纯数据库的角度进行分析。这是一个普通表(非分区表),按照主键字段的范围查询一批记录并进行清理。
按照正常理解,执行索引范围扫描应该是效率较高的一种处理方式,但实际情况都是全表扫描。进一步分析发现,该表的主键是没有业务含义的,仅仅是自增长的数据,其来源是一个序列。
但奇怪的是,这个主键字段的类型是变长文本类型,而不是通常的数字类型。当初定义该字段类型的依据,现在已经无从考证,但实验表明正是这个字段的类型“异常”,导致了错误的执行路径。
下面通过一个实验重现这个问题。
1)数据准备
两个表的数据类型相似(只是ID字段类型不同),各插入了320万数据,ID字段范围为1~3200000。
createtablet1asselect*fromdba_objectswhere1=0;
altertablet1addidintprimarykey;
createtablet2asselect*fromdba_objectswhere1=0;
altertablet2addidvarchar2(10)primarykey;
insertintot1
select"test","test","test",rownum,rownum,"test",sysdate,sysdate,"test","test","","","",rownum
fromdual
connectbyrownum<=3200000;
insertintot2
select"test","test","test",rownum,rownum,"test",sysdate,sysdate,"test","test","","","",rownum
fromdual
connectbyrownum<=3200000;
commit;
execdbms_stats.gather_table_stats(ownname=>"hf",tabname=>"t1",cascade=>true,estimate_percent=>100);
execdbms_stats.gather_table_stats(ownname=>"hf",tabname=>"t2",cascade=>true,estimate_percent=>100);2)模拟场景
相关代码如下:
select*fromt1whereid>=3199990;
11rowsselected.
--------------------------------------------------------------------------------
|Id|Operation|Name|Rows|Bytes|Cost(%CPU)|Time|
---------------------------------------------------------------------------------
|0|SELECTSTATEMENT||11|693|4(0)|00:00:01|
|1|TABLEACCESSBYINDEXROWID|T1|11|693|4(0)|00:00:01|
|*2|INDEXRANGESCAN|SYS_C0025294|11||3(0)|00:00:01|
---------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1recursivecalls
0dbblockgets
6consistentgets
0physicalreads对于普通的采用数值类型的字段,范围查询就是正常的索引范围扫描,执行效率很高。
select*fromt2whereid>="3199990";
755565rowsselected.
--------------------------------------------------------------------------
|Id|Operation|Name|Rows|Bytes|Cost(%CPU)|Time|
--------------------------------------------------------------------------
|0|SELECTSTATEMENT||2417K|149M|8927(2)|00:01:48|
|*1|TABLEACCESSFULL|T2|2417K|149M|8927(2)|00:01:48|
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1recursivecalls
0dbblockgets
82568consistentgets
0physicalreads对于文本类型字段的表,范围查询就是对应的全表扫描,效率较低是显而易见的。
3)分析结论
- 字符类型在索引中是“乱序”的,这是因为字符类型的排序方式与我们的预期不同。从“select * from t2 where id>= "3199990"”执行返回755 565条记录可见,不是直观上的10条记录。这也是当初在做表设计时,开发人员没有注意的问题。
- 字符类型还导致了聚簇因子很大,原因是插入顺序与排序顺序不同。详细点说,就是按照数字类型插入(1..3200000),按字符类型("1"..."32000000")t排序。
selecttable_name,index_name,leaf_blocks,num_rows,clustering_factor
fromuser_indexes
wheretable_namein("T1","T2");
TABLE_NAMEINDEX_NAMELEAF_BLOCKSNUM_ROWSCLUSTERING_FACTOR
---------------------------------------------------------------------------
T1SYS_C00252946275320000031520
T2SYS_C0025295132713200000632615- 在对字符类型使用大于运算符时,会导致优化器认为需要扫描索引大部分数据且聚簇因子很大,最终导致弃用索引扫描而改用全表扫描方式。
4)解决方法
具体的解决方法如下:
select*fromt2whereidbetween"3199990"and"3200000";
--------------------------------------------------------------------------------
|Id|Operation|Name|Rows|Bytes|Cost(%CPU)|Time|
--------------------------------------------------------------------------------
|0|SELECTSTATEMENT||6|390|5(0)|00:00:01|
|1|TABLEACCESSBYINDEXROWID|T2|6|390|5(0)|00:00:01|
|*2|INDEXRANGESCAN|SYS_C0025295|6||3(0)|00:00:01|
--------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1recursivecalls
0dbblockgets
13consistentgets
0physicalreads将SQL语句由开放区间扫描(>=),修改为封闭区间(between xxx and max_value)。使得数据在索引局部顺序是“对的”。如果采用这种方式仍然走全表扫描,还可以进一步细化分段或者采用“逐条提取+批绑定”的方法。
2. 给我们的启示
这是一个典型的由不好的数据类型带来的执行计划异常的例子。它给我们带来如下启示:
- 糟糕的数据结构设计往往是致命的,后期的优化只是补救措施。只有从源头上加以杜绝,才是优化的根本。
- 在设计初期能引入数据库审核,可以起到很好的作用。

案例03 规范SQL写法好处多
1. 案例说明
某大型电商公司数据仓库系统,开发人员反映作业运行缓慢。经检查是一个新增业务中某条SQL语句导致。经分析是非标准的SQL引起优化器判断异常,将其修改成标准写法后,SQL恢复正常。
1)具体分析
看下面的代码:
select...from...
where
(
(
order_creation_date>=to_date(20120208,"yyyy-mm-dd")and
order_creation_date<to_date(20120209,"yyyy-mm-dd")
)
or
(
send_date>=to_date(20120208,"yyyy-mm-dd")andsend_date<to_date(20120209, "yyyy-mm-dd")
)
)
andnvl(a.bd_id,0)=1
--------------------------------------------------------------------------------
|Id|Operation|Name|Cost(%CPU)|Time|Pstart|Pstop|
--------------------------------------------------------------------------------
|0|SELECTSTATEMENT||2470K(100)||||
|1|SORTGROUPBY||||||
|2|TABLEACCESSBYGLOBALINDEXROWID
|XXXX|5(0)|00:00:01|ROWL|ROWL|
|3|NESTEDLOOPS||2470K(1)|08:14:11|||
|4|VIEW|VW_NSO_1|2470K(1)|08:14:10|||
|5|FILTER||||||
|6|HASHGROUPBY||2470K(1)|08:14:10|||
|7|TABLEACCESSBYGLOBALINDEXROWID
|XXXX|5(0)|00:00:01|ROWL|ROWL|
|8|NESTEDLOOPS||2470K(1)|08:14:10|||
|9|SORTUNIQUE||2340K(2)|07:48:11|||
|10|PARTITIONRANGEALL
||2340K(2)|07:48:11|1|92|
|11|TABLEACCESSFULL
|XXXX|2340K(2)|07:48:11|1|92|
|12|INDEXRANGESCAN
|XXXX|3(0)|00:00:01|||
|13|INDEXRANGESCAN|XXXX|3(0)|00:00:01|||
--------------------------------------------------------------------------------这个SQL中涉及的主要表是一个分区表,从执行计划(Pstart、Pstop)中可见,扫描了所有分区,分区裁剪特性没有起效。
2)解决方法
见下面的代码:
select...
from...
where
order_creation_date>=to_date(20120208,"yyyy-mm-dd")and
order_creation_date<to_date(20120209,"yyyy-mm-dd")
unionall
select...
from...
where
send_date>=to_date(20120208,"yyyy-mm-dd")and
send_date<to_date(20120209,"yyyy-mm-dd")and
nvl(a.bd_id,0)=5尝试通过引入union all来分解查询,以便于优化器做出更准确的判断。采用这个方法后,确实起效了,当然不可避免会扫描两遍表。
select...
from...
where
(
(
order_creation_date>=to_date(20120208,"yyyymmdd")and
order_creation_date<to_date(20120209,"yyyymmdd")
)
or
(
send_date>=to_date(20120208,"yyyymmdd")and
send_date<to_date(20120209,"yyyymmdd")
)
);
--------------------------------------------------------------------------------
|Id|Operation|Name|Cost(%CPU)|Time|Pstart|Pstop|
--------------------------------------------------------------------------------
|0|SELECTSTATEMENT||42358(1)|00:08:29|||
|1|SORTAGGREGATE||||||
|2|CONCATENATION||||||
|3|PARTITIONRANGESINGLE
||17393(1)|00:03:29|57|57|
|*4|TABLEACCESSFULL
|XXXX|17393(1)|00:03:29|57|57|
|*5|TABLEACCESSBYGLOBALINDEXRO