近日,ChatGPT横空出世的消息霸屏网络,其开放的短短4天时间,用户量即达到百万级,注册用户之多导致服务器一度爆满。菲斯科作为一家创新型大数据服务公司,积极拥抱新技术的浪潮,并将ChatGPT集成到其核心产品FiData的"数据工厂"模块中,进一步简化和加速数据处理流程,让数据处理变得更简单,更快一步!

1
目前数仓建模的难点与痛点
重复工作,缺乏标准,维护难度大
以数仓建模为例,在传统的数据仓库开发中,通常需要架构师设计数据库分层,再由数据开发工程师实现上游系统数据对接、数据维度事实转换等ETL工作。这个过程涉及大量SQL编写、建表等重复工作,开发管理规范不同导致后期运维成本过高,数据溯源排查难度大等问题,同时由于工程师个人技能水平的差异,增加了项目失败的风险等。
Fidata的诞生从一定程度上解决了这些问题。相比于传统的数据仓库开发方式,其具备以下优势:
- 减少重复工作
将建表、开发规范以及表数据的血缘追溯等纳入产品体系中,减少了工程师不必要的重复工作;
- 提高项目成功率
Fidata的产品框架标准化了命名、规范、文档等,并引入自动化工具,可以有效地避免个人水平差异和开发管理规范不同等问题,从而提高项目成功率;
- 简化开发流程
大大简化了开发人员学习数仓理论知识的难度,同时将后台分层和建表逻辑交由产品框架来处理,使得开发流程更加简化;
- 提高运维效率
实现了表数据的血缘追溯功能,可以帮助后期项目数据排查溯源,从而提高运维效率。
总之,Fidata“数据工厂”以一种新型的数据处理架构,通过产品化的方式帮助企业快速建立数仓,提高项目成功率、降低开发成本和运维成本。
FiData 之“数据工厂”
更高效率,更低成本,可维护性
FiData是菲斯科自研的一款以业务为导向的数据中台产品,提供从数据接入到数据消费一站式数据管理与应用能力。作为一个产品套件,共由七个组件构成,包括:数据工厂、主数据管理、数据消费、报表门户、数据资产管理、数据运维和数据萃取。
“数据工厂”是FiData的一个重要组成部分之一。它将数据仓库、ETL、数据调度等组件集成在一起,形成一个可扩展、易维护的数据处理平台。相比于传统的数据仓库建设方式,数据工厂具有更高的效率、更低的开发成本和更好的可维护性。
集成ChatGPT,智能小助手上线
工程师们的智能小帮手!
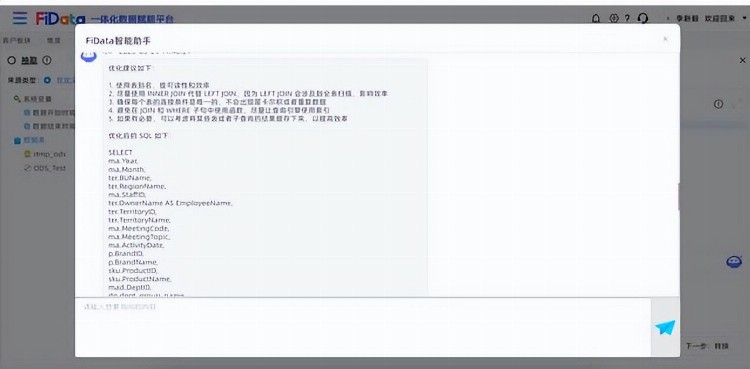
当工程师们只需要编写SQL业务逻辑时,仍然可能会面临性能差、查询脚本编写不规范、无法完成血缘追溯等问题。这些问题都会影响数据开发的质量和效率,甚至导致项目的失败。为了解决这些问题,我们将ChatGPT集成到Fidata产品中,智能小助手小F上线!
ChatGPT是一种基于深度学习的语言模型,它可以理解人类语言并生成自然语言响应。通过与FiData相结合,ChatGPT智能小助手,为每个用户提供智能化的数据开发服务,实现许多有用的功能,例如:
- 自动纠正SQL查询脚本中的错误和不规范代码,从而优化查询性能和结果;
- 为工程师提供实时技术支持,解答疑问和提供建议,从而提高数据开发的效率和质量;
- 工作累了,甚至还能打开窗口和小F调侃两句,放松疲惫的身心~
未来,随着数据技术和市场需求的不断变化和升级,FiData将会不断探索前沿技术和应用场景,为用户提供更高水准、更极致的数据赋能服务。