机器之心报道
机器之心编辑部
在近日举办的微软开发者大会 Microsoft Build 2023 上,OpenAI 联合创始人 Andrej Karpathy 做了一个题为《State of GPT》演讲,其中他首先直观地介绍了 GPT 的训练流程的各个阶段,然后展示了如何使用 GPT 来完成任务并给出了直观的示例,最后他还给出了一些非常具有实际意义的使用建议。机器之心详细整理了该演讲,以飨读者。

视频地址:https://youtu.be/bZQun8Y4L2A
如何训练 GPT?
首先,我们概括性地看看 GPT 大模型的训练流程。要记住,这是个新领域,变化很快。现在的流程是这样,以后新技术出现时可能会不一样。

可以看到,GPT 的训练流程可粗略分为四个阶段:预训练、监督式微调、奖励建模、强化学习。
这四个阶段按顺序进行。每个阶段都有各自的数据集,每个阶段也有各自用于训练神经网络的算法。第三行是所得到的模型。最后底部有一些备注信息。
在所有阶段中,预训练阶段所需的计算量是最大的,可以说 99% 的训练计算时间和浮点运算量都集中在这个阶段。因为这一阶段需要处理超大规模的互联网数据集,可能需要数千 GPU 构成的超级计算机工作几个月时间。其它三个阶段都算是微调(fine tuning)阶段,所需的 GPU 数量和训练时间都少得多。
下面我们将分阶段详解 GPT 的整个训练流程。
预训练阶段
预训练阶段的目标是得到一个基础模型。
首先第一步:数据收集。这一阶段需要海量的数据,下面给出了一个例子,这是来自 Meta 的 LLaMA 模型的数据混合(data mixture)方法:
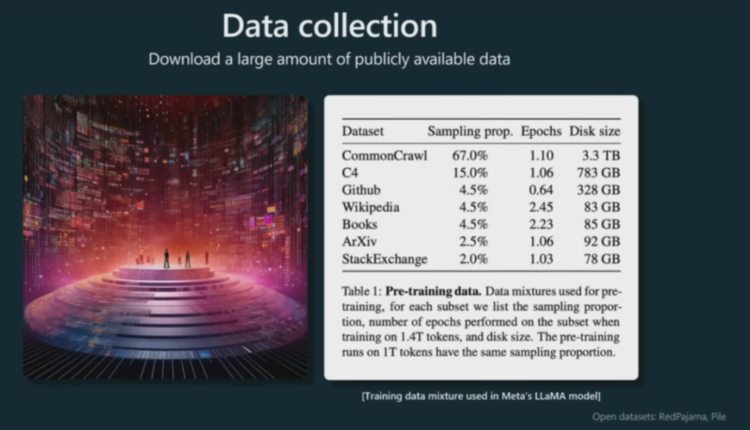
可以看到,LLaMA 的预训练数据按不同比例混用了多个不同类型的数据集,其中比例最大的是爬取自互联网的 CommonCrawl 以及基于 CommonCrawl 构建的 C4,此外还有 GitHub、维基百科等数据集。
收集到这些数据之后,还需要对它们进行预处理,这一步也被称为「token 化」。简单来说,这就是一个转译过程,即把原始文本转译成某种整数序列,因为这种整数序列就是 GPT 实际工作时所操作的本地表征。

这种从文本到 token 和整数的转译过程是无损的,而具体执行这一过程的算法有好几种。举个例子,如上图所示,我们可以使用一种名为字节对编码(byte pair encoding)的技术,其工作方式是迭代式地合并短文本块并将它们分组成 token。最后实际输入 Transformer 的就是那些整数序列。
下面来看两个示例模型 GPT-3 和 LLaMA 在预训练阶段需要考虑的一些主要的超参数。Karpathy 表示由于他们还没有发布有关 GPT-4 的相关信息,因此在演讲中使用了 GPT-3 的数据。
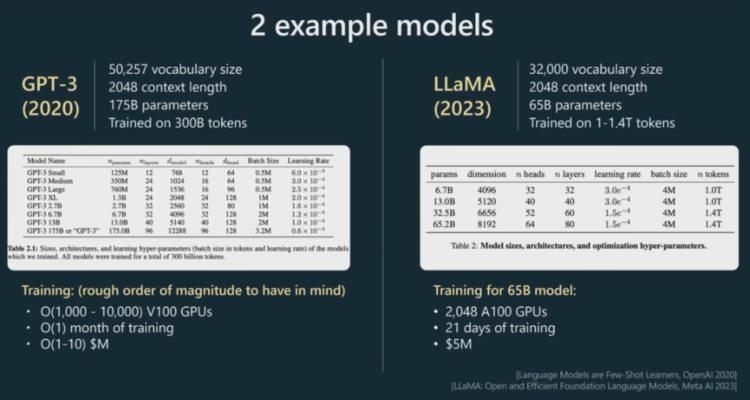
可以看到,词汇库的大小通常是 10000 数量级的;上下文长度通常为 2000 或 4000 左右,而现在更是有长达 10 万的。上下文长度决定着 GPT 在预测序列的下一个整数时所查看的最大整数数量。
对于参数数量,可以看到 GPT-3 的为 1750 亿,而 LLaMA 的为 650 亿,但实际上 LLaMA 的性能表现远胜于 GPT-3。原因何在?因为 LLaMA 训练的 token 要长得多,达到了 1.4 万亿,而 GPT-3 仅有大约 3000 亿。因此,评价一个模型时,光看参数数量是不够的。
上图中部的表格中给出了 Transformer 神经网络中一些需要设定的超参数,比如头的数量、维度大小、学习率、层数等等。
下方则是一些训练超参数;比如为了训练 650 亿参数的 LLaMA 模型,Meta 使用 2000 个 GPU 训练了大约 21 天,资金成本大约为 500 万美元。这大概能体现出预训练阶段各项成本的数量级。
接下来看实际的预训练过程究竟会发生什么。大致来说,首先会把 token 分批组成 data batch。这些分配数据构成数组,再被输入到 Transformer 中。这些数组的大小为 B×T;其中 B 是分批大小,即堆叠的独立样本的行数;T 是最大上下文长度。下图给出了一个示例。

在图中示例中,上下文长度 T 仅为 10,但实际模型的 T 可达到 2000 或 4000 乃至更长。也就是说,实际模型的一行数据可以非常长,比如一整个文档。我们可以将许多文档打包到各行中,并用这些特殊的文本结束 token <|endoftext|> 来分隔它们。简单来说,这些 token 是告诉 Transformer 新文档开始的位置。比如图中的 4 行文档就转换成了底部的 4×10 的数组。
现在,需要将这些数字输入到 Transformer。这里我们仅看其中一个单元格(绿色),而实际上每个单元格都会经历同样的处理流程。
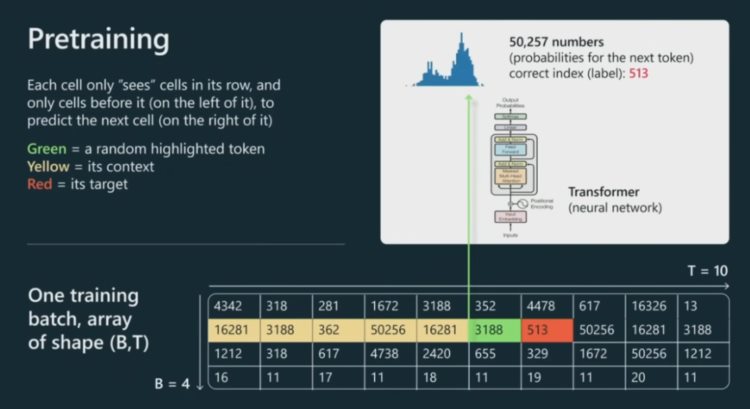
这个绿色单元格会查看其之前的所有 token,即所有黄色单元格的 token。我们要将这里的全部上文输入到 Transformer 神经网络,Transformer 则需要预测出该序列的下一个 token,即图中的红色 token。
为了给出准确的预测,神经网络需要调整其上百亿个参数。每次调整后,神经网络对每个单元格 token 的预测分布就会不同。举个例子,如果词汇库的大小为 50257 个 token,那么我们就需要同样多的数字,以便得到下一个 token 的概率分布,其预测了下一个 token 的可能值及相应概率。
在图中的示例中,下一个单元格应该是 513,因此就可以将其用作监督源来更新 Transformer 的权重。我们可以并行地对每个单元格采取同样的操作。我们不断更换数据批,努力让 Transformer 有能力正确地预测序列的下一个 token。
下面再看一个更具体的示例。这是《纽约时报》用莎士比亚作品训练的一个小型 GPT。这里给出了莎士比亚作品中的一小段以及在其上训练 GPT 的情况。
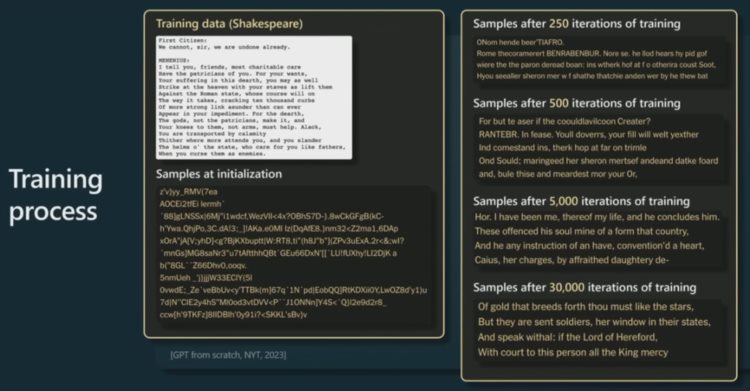
首先,在 GPT 初始化时,权重是完全随机的,所以其输出结果也是完全随机的。随着时间推移,训练时间越来越长,GPT 不断迭代,模型给出的结果样本也就越来越连贯通顺了。最后,可以看到 Transformer 学到了一些有关词的东西,也知道应该在哪些地方放置空格了。
在实际预训练过程中,要通过一些量化指标来确定模型迭代中的表现变化。一般来说,研究者监测是损失函数。损失低说明 Transformer 更可能给出正确预测,即序列中下一个整数是正确值的概率更高。
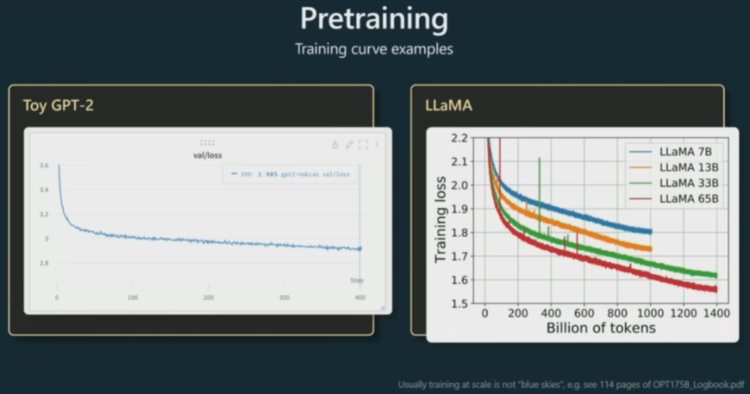
预训练其实就是一个语言建模过程,这个过程的训练时间可长达一个月。之后,GPT 学到了一个非常强大的通用型语言表征。然后我们可以针对具体的下游任务高效地对其进行微调。
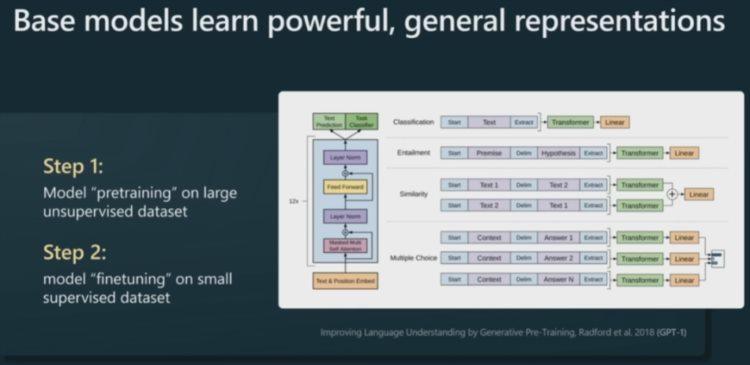
举个例子,如果下游任务是情绪分类。过去,你采用的方法可能是收集大量标注好「正面」或「负面」情绪的样本,然后训练一个 NLP 模型。但现在的新方法不需要预先做情绪分类了,你只需要拿一个预训练过的大型语言模型,然后只需要少量示例样本,就能非常高效地针对你的具体任务对模型进行微调。
这对实际应用来说非常有用。那么为什么预训练后的大型语言模型(LLM)只需要简单微调就能用呢?这是因为语言建模过程本身就已经涵盖了大量任务 —— 模型为了预测下一个 token,必须理解文本的结构以及其中内含的各种不同概念。
这就是 GPT-1。
现在来看 GPT-2。人们注意到 GPT-2 甚至可以不用微调就能非常有效地让这些模型执行 prompt。这些语言模型的训练目标是完成文档,因此用户实际上只需通过编排适当的虚假文档,就可以诱导模型执行具体任务。下面给出了一个例子。

其中给出了一篇文章,用户想完成的任务是做相关的问答。因此,只需要在文章后面加几个有答案的问答(这被称为 few-shot prompt),然后再提问,那么由于 Transformer 的目标是完成这个文档,也就相当于回答了问题。这个例子是用 prompt 来调教基础模型,使其相信它在模仿一个文档,结果却完成了问答任务。
Karpathy 认为,以提供 prompt 替代微调的方式昭示着大型语言模型的新时代。这让基础模型本身就足以应对许多不同类型的任务。
也因此,相关领域的研究前沿就转向了基础模型的进化。各大研究机构和企业都在打造自己的基础大模型。不过这些模型并不都是公开可用的,比如 OpenAI 一直没有发布 GPT-4 基础模型。我们通过 API 调用的 GPT-4 模型其实并不是基础模型,而是一个助理模型(assistant model)。
GPT-3 基础模型可通过 DaVinci API 使用,GPT-2 基础模型也是公开的,用户甚至可以在 GitHub 上找到其参数权重配置:https://github.com/openai/gpt-2 。不过总体而言,目前最开放的基础模型还是 Meta 的 LLaMA 系列模型,但该系列也没有授权给商业使用。
现在需要指出一点:基础模型不等于助理模型。基础模型不会回答用户提问,它们只会完成文档。所以如果你对基础模型说:「写一首关于面包和奶酪的诗」,你可能不会如愿 —— 它只会把你的要求看成一个文档,然后试图完成它。

但是,你可以通过适当的 prompt 诱导基础模型写诗,如上图右侧所示。
当然,你也可以诱导模型变成助理。为此,你需要创建一些特定的少样本 prompt,使其看起来像是人类与助理交换信息的交互过程的文档。如下图所示,然后你只需要在文档结尾处附上你的提问,基础模型就能在一定程度上化身为一个有用的助理,给出某个答案。但这个过程并不非常可靠,实践效果也不好。
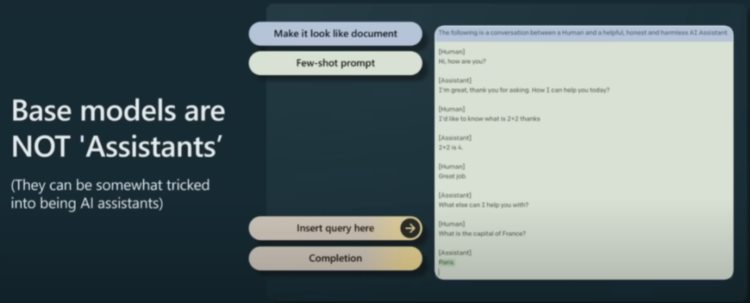
因此,为了打造出真正的 GPT 助理,需要另外的方法,即监督式微调(supervised fine tuning,即 SFT)。
监督式微调阶段
在监督式微调阶段,需要收集少量但高质量的数据集。OpenAI 的方法是以人工方式收集由 prompt 和理想响应构成的数据。这些数据需要不少,一般需要几万个。
然后,继续在这些数据上执行语言建模。算法不变,只是换了训练数据集:从大量低质量的互联网文档换成了少量高质量的问答式「prompt - 响应」数据。
这个训练过程完成后,就得到了一个 SFT 模型。部署这些模型就能得到助理,它们已经能完成一定程度的工作。
依然来看个例子。这是人类合同工写出的数据,其中有一个 prompt,然后人类再写出理想的响应。

理想的响应自然不能让人随意发挥,而是需要遵循许多规则(如上右图),其中有格式上的要求并且要保证给出的答案有用、真实可信且无害。
接下来还需要基于人类反馈的强化学习(RLHF),其中包含奖励建模阶段和强化学习阶段。
奖励建模阶段
在这一阶段,需要将数据收集转变成比较的形式。这里给出了一个示例。对于同样的 prompt,即要求助理写一个能检查给定字符串是否为回文的程序或函数。再使用已经训练好的 SFT 模型生成多个结果,这里给出了三个。然后再让人类给这些结果排名。
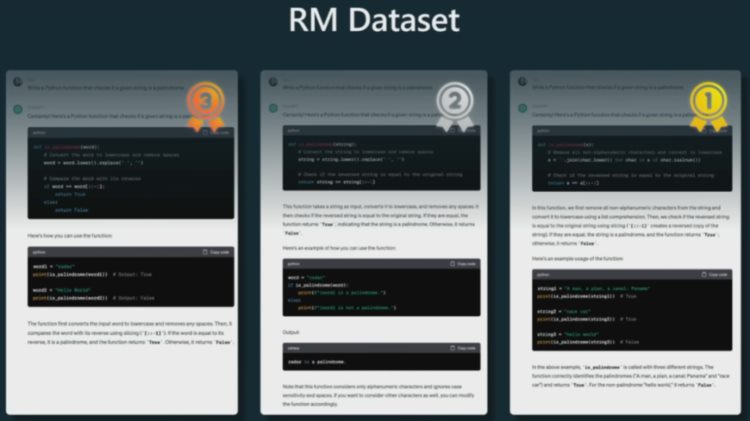
这件事做起来可并不简单,毕竟要是让人类来完成一个 prompt,可能需要耗费几个小时时间。现在假设排名完成了,然后就需要在这些结果的所有可能配对上执行类似二元分类的操作。
如下图所示,具体的做法是这样的:将 prompt 按行排列;这里的三行 prompt 是一样的,但完成的结果不同,即图中黄色 token(来自 SFT 模型)。然后在其后添加一个特殊的奖励读出 token。这样,只需要在绿色 token 位置对 Transformer 执行监督,就能使 Transformer 预测出某个奖励,从而判断 prompt 的完成结果是否优良。

这基本上就是让 Transformer 猜测每个完成结果的质量。当其猜测完每个不同结果的质量后,开发者就可以动用已有的基本真值(ground truth)强行让某些结果的质量分数高于其它结果,从而使模型的奖励预测结果与人工给出的基本真值保持一致。这个过程可以通过一个损失函数完成。
有了奖励模型之后,GPT 依然还不能成为一个有用的助理,但奖励模型却对后面的强化学习阶段很有用,因为奖励模型可以评估任意给定 prompt 的任意完成结果的质量。
强化学习阶段
强化学习阶段做的事情就是基于奖励模型,使用强化学习算法对大量 prompt 对应的结果进行评分。
这里以一个 prompt 为例,将 SFT 模型完成的结果(黄色)排列成行,然后在后面加上奖励 token(绿色)。这些奖励来自奖励模型,并且已经固定不变。

现在使用同样的语言建模损失函数,只是现在是在黄色 token 上训练,并根据奖励模型指示的奖励来重新权衡语言建模目标。
比如在第一行,奖励模型认为这个完成结果的评分相当高。因此,模型在第一行采样的所有 token 都会得到强化,也就是在未来会有更高的概率被采用。对比之下,奖励模型不喜欢第二个完成结果,给出了负分评价,因此该行的所有 token 在未来出现的概率就会降低。
如此这般在许多 prompt 上操作一遍又一遍,经过许多数据批次,就能得到一个创建黄色 token 的策略。依照这个策略,所有完成结果都能被奖励模型给予高分。
这就是 RLHF 的训练流程。最后得到的模型就可以部署成应用了。
ChatGPT 就是一个 RLHF 模型,而其它一些模型则可能是 SFT 模型,比如 Claude 等。
那么 OpenAI 为什么要使用 RLHF 呢?Karpathy 表示,原因很简单,使用 RLHF 能让模型表现更好。根据 OpenAI 之前做的一些实验,可以看到使用了 PPO(近端策略优化)算法的 RLHF 模型整体上都更好一些。当把结果提供给人类时,相比于 SFT 模型和通过 prompt 化身为助理的基础模型,人类也基本更喜欢来自 RLHF 模型的 token。
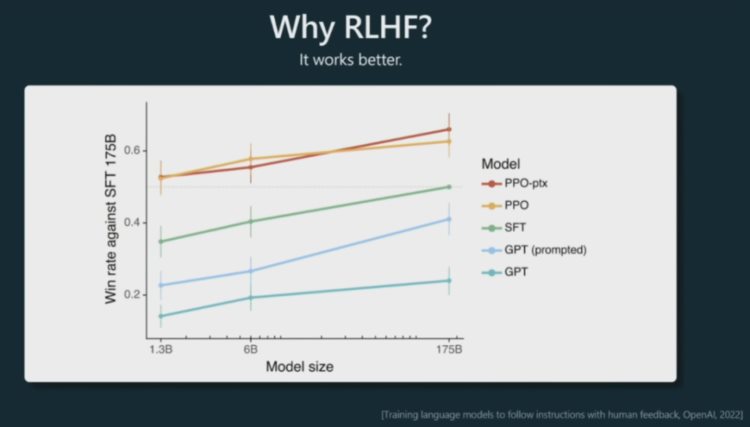
那 RLHF 为什么能让模型更好呢?目前 AI 研究界还没有找到一个得到大家认可的理论,但 Karpathy 还是给出了自己的见解。他认为这可能与比较和生成的计算难度之间的不对称性有关。
举个例子说明一下:假设我们要让一个模型写一首关于回形针的俳句。如果你是一位正努力创建训练数据的合同工,正在为 SFT 模型收集数据。那么你该怎样写出一首关于回形针的好俳句呢?而你可能并不是一位优秀的俳句诗人。但是,如果给你几首俳句,你却有能力辨别它们中哪首更好一些。也就是说,比起创建一个好样本,判断哪个样本更好是简单得多的任务。因此,这种不对称性可能使得比较是一种更好的方法 —— 能更好地利用人类的判断来创造出好一些的模型。

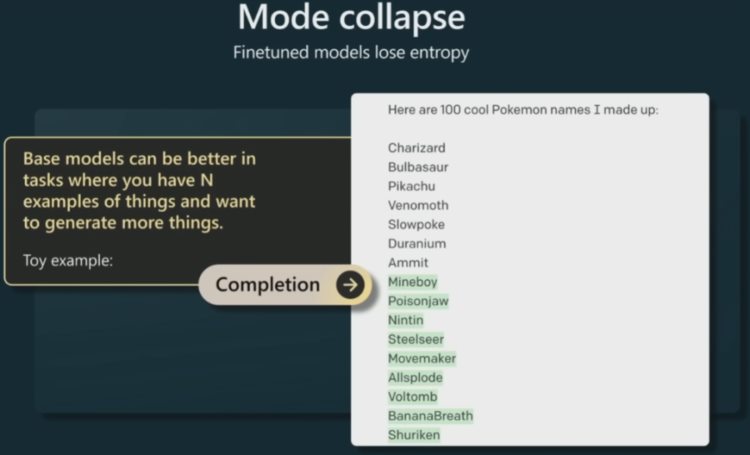
现在来看另一个方面:RLHF 并不总是会为基础模型带来提升。在某些情况下,RLHF 模型会失去一些熵,也就是说它们会输出更加单调、变化更少的结果。而基础模型的熵更高,可以输出更加多样化的结果。

比如下面的任务可能就更适合使用基础模型,即生成与已有的 n 个示例相似的东西。这里的示例任务是生成更多宝可梦名字。首先,用户向模型提供了 7 个宝可梦名字,然后让基础模型完成文档。基础模型生成了大量宝可梦名字。这些名字都是虚构的,毕竟宝可梦并不真实存在。Karpathy 认为这类任务使用基础模型会得到更好的结果,因为基础模型的熵更高,给出的结果既与之前的示例相似,又更加多样化和炫酷。
现在,用户可以使用的助理模型已有不少了。伯克利有个团队正对许多助理模型进行排名并给出了基本的 ELO 评分。当然,现目前最好的模型是 GPT-4;Claude 和 GPT-3.5 紧随其后。有些模型公开提供模型权重,比如 Vicuna、Koala 等。在这个榜单中,前三名都是 RLHF 模型,其它模型基本都是 SFT 模型。

上一篇:万和:扎根IT教育三十载