训练文本到语音模型通常需要更多或更长的样本,但微软开发的VALL-E可以从三秒钟的音频剪辑中克隆出任何人的声音。网络安全专家表示,如果没有适当的限制措施,它可能被用于网络钓鱼攻击或传播错误信息。
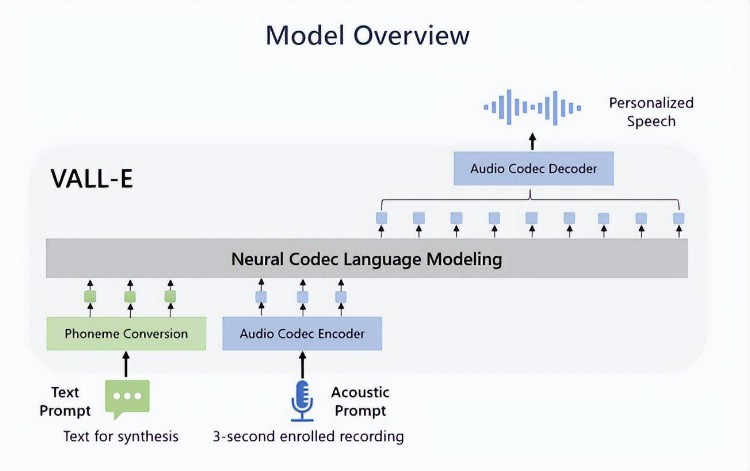
除了减少生成新声音的训练时间之外,VALL-E通过保留原始样本的语调、魅力和风格,创造出比其他模型更自然的合成声音。在编写文本转语音脚本时,可以根据需要对这些参数进行调整。
拥有这些功能意味着,只要从某人的电话、会谈甚至播客中录下三秒钟的声音,该模型就可以将其声音合成为任何语音,例如可能会让政客、演员甚至家庭成员说出转帐或付款的话语。
微软表示,与之前的合成语音模型相比,VALL-E的性能有所提高,以至于人们很难分辨声音的真假。
就像用于训练DALL-E2和GPT-3的大型生成式人工智能模型一样,开发人员向人工智能系统中输入了大量的音频材料进行训练。在训练模型时,他们使用了长达6万小时的演讲录音,其中大部分来自使用视频会议Teams应用程序录制的录音。
VALL-E的使用场景
微软目前还没有对外开放VALL-E的代码,只是发布了使用该工具生成的示例音频文件。目前还不清楚微软何时或是否计划将VALL-E作为公共访问或商业工具提供。
人工智能开发商Tovie.AI首席执行官Joshua Kaiser表示,该模型的设计方式允许用户采用更少的数据做更多的事情,这对于那些试图创建语音合成的开发商来说至关重要,因为这些公司没有足够的数据来提高性能。他说:“我们认为,这将使许多行业受益,例如零售业、金融科技业以及游戏行业,这些行业已经开始采用语音界面,使整个过程更容易访问。”
Gartner副总裁兼分析师Arun Chandrasekaran表示,VALL-E最大的好处在于其潜在的规模。它可以在“零样本”或“少样本”场景中有效,在这些场景中,很少有特定领域的训练数据可用。他说:“此外,如果这些模型可以作为云计算服务交付,与传统方法相比,它们可以减少建立和运行模型所需的时间和精力。”
Chandrasekaran解释称,这项技术在现实世界中有几个用例,包括语音编辑(可以纠正某个单词或句子),不同场景下的语音背景化,交互式虚拟学习,以及客户服务自动化。
VALL-E的使用确实存在风险,包括欺骗语音识别或模仿特定的演讲者和名人,这可能会导致错误信息的快速传播。这可能是微软迟迟不发布该技术背后的代码或发布API的原因,就像OpenAI和其他公司对GPT-3和DALL-E2等文本和图像生成工具所做的那样。这将使采用真实声音进行网络钓鱼攻击,或通过YouTube视频或播客在网上传播假新闻变得更容易。
VALL-E的欺诈风险
网络欺诈可能包括允许网络犯罪者访问使用声纹作为密码的银行或安全系统,尽管其中许多系统都有检测实时声音还是录音声音的机制。它也可以用于网络钓鱼骗局,从电话中提取简短的语音样本,然后使用该样本创建一个新的语音模型,可以更容易地说服某人透露密码,也可能欺骗一些公司的财务经理。
互联网安全解决方案供应商Check Point Software安全工程师Muhammad Yahya Patel表示,VALL-E等技术的进步不应该令人担忧,但仍应谨慎对待此类系统。他说,“尽管VALL-E有其显著的优点,但随着它越来越成熟并融入我们的日常生活,微软新的VALL-E文本到语音模型可能会对网络安全产生一些令人担忧的影响。如果说我们从去年吸取了什么教训的话,那就是网络犯罪分子会利用任何途径诱骗毫无戒心的受害者,让他们透露重要的密码或财务信息。诈骗电话是威胁行为者常用的一种方法,考虑到这些活动的成功率,这种担忧是有充分理由的。”
他表示,这项新技术可能会给网络犯罪分子提供升级技术的机会,并引入个人元素,包括允许他们模仿受害者熟悉的人员的声音。“这将使任何人都很难区分他们信任的人的请求和网络罪犯分子的请求。同样,随着我们走向银行现在都在使用语音认证来授权交易的时代,很容易看到网络犯罪分子以个人为目标获得帐户的访问权限。关键是要理解黑客利用新技术的机会,并因此采取必要的预防措施。”
行业媒体已经联系微软就其如何减轻VALL-E的潜在滥用发表评论,但未予置评。