名师介绍:
大家好,我是郭一军。


云贝数据创始人,腾讯云TVP,PostgreSQL ACE,腾讯云高级认证讲师,Oracle MySQL高级认证讲师,中国PostgreSQL分会高级认证讲师。ITPUB管理版资深版主,精通Oracle DSI(Data Server Internals),拥有Oracle OCM,阿里云ACE,AWS SAP等高级IT认证。从业20年,拥有十几年数据库的工作经验,历任过连连支付首席DBA、唯品会高级数据库专家、吉利汽车研究院云计算平台技术负责人。负责连连支付核心交易库的开发与运维、经历唯品会大规模(5000+个实例)MySQL数据库的架构设计和运维,主导吉利汽车上亿级的私有云项目及自能驾驶200Pb数据存储架构设计。有10+年的数据库授课经验,曾给腾讯技术区域中心、建设银行、招商银行、平安银行、上海农商行、浙农信、昆山农商行、中国金融期货交易中心,浙江电力,安徽电力,浙江大学,武汉达梦,杭州邮储银行、安徽电信,浙江电信,嘉兴烟草等企业开展内训。针对个人的培训所培训学员遍布全球各个企业(有索尼、西门子、花旗、腾讯、阿里、百度、中兴、美团等公司),并在企业内负责重要的数据相关工作,已培训学员超10000+(OCM 500+,OCP 3000+,TDSQL TCP 100+,技术赋能7000+),深受学员好评。
今天我要分享的内容:
第一个:什么是分布式数据库。
第二个:用一个具体的场景来理解分布数据库,从分布数据库事务的操作过程来解析分布式的一个工作流程。
第三个:重点会讲到分布式事务里面比较重要的两阶段提交内部机制。
第四个:分布式数据库里面有一个非常重要的技术就是怎么去实现全局一致性读。
1. 什么是分布式数据库?
什么是分布式数据库?分布数据库在分布系统数据库系统原理第三版描述是把分布式数据库定义为一群分布在计算机网络上逻辑上相互关联的数据库,实际上就是数据库也是基于DBMS的就是关系型数据库的一个底座, 对于分布式对用户来说是透明的,也就是说用户去使用分布数据库,就像用我们用单机的数据库一样,就是不用做任何特殊的配置这样去使用,为什么会出现分布式数据库?
数据库的发展有三个阶段, 在2008年之前,数据库是基于单机版的这种RDBMS这个代表主要是以Oracle,MySQL为主要的关系型数据库。
所以我们可以看到在数据库引擎的排行榜上,像Oracle,MySQL还是排到第一名第二名,也就是说数据库还是以集中式的数据库为主。从2008年到2013年之间,随着移动互联网的发展,数据量变的越来越大,已经满足不了海量的数据存储,所以就产生了NoSQL(not only SQL), 主要是以MongoDB ,Redis HBase的这样的数据库就能很轻松的解决海量数据存储的问题,但它的数据库事务(ACID属性)比较弱一点。
随着2003年之后到现在,我们的互联网金融、银行、证券以及电信的计费等等这样的业务场景,它的数据量越来越大,我们除了要满足数据量越来越大,我还要满足什么?
就是事务的特性ACID,所以在2003年到现在,主要以New SQL为主,我们现在把New SQL也叫做分布式数据库, 分布数据库有两大特性,其中一个是CAP的理论,C就是一致性,A就是可用性,P就是网络分区容错性。
对于分布式的话,必须要满足P特性,分布式数据库基本上必须满足 C一致性和P这两个特性为主。
A我们理解就是可用性,就是说如果用了分布数据库可能在可用性上面比较弱一点,它可能在一段时间可能不可用,所以说 CAP理论是当中,满足 C一致性和P这两个特性为主。
当然在数据库的分布当中,还有一个比较重要的叫BASE理论,就是数据这个数据可以处在中间状态。还有最终一致性,在分布式数据库中有些数据处在中间状态怎么去处理?我们通过简单的理解分布数据库两个特性CAP和BASE理论以及分布数据库的发展。
刚才我们讲了分布式数据库的产生, 对于它的产生,之前大家经常会听到数据库MySQ分库分表,但现在我们很少去说数据库分库分表,都在说分布式数据库,重点是是国产的分布式数据库,不管是数据库分库分表,还是分布式数据库,对于分布式数据库产生,它是怎么产生的?刚才我也解释了,它有两大特点:
第一个解决数据的海量存储,这是很重要的一点,就是单机 Oracle很难解决海量数据存储,分布式数据库数据存储可以达到几百T、上P级数据。
第二个从数据库的性能上来看,从响应时间分析,直接从在磁盘上读数据,它的性能会比较差,也就是说一台主机服务器配置了大量的磁盘(8T*12=96T),但是内存(512G)、CPU是有限的,它解决不了我们的响应时间延时问题,所以我们必须要把通过分布式数据库把数据从磁盘上拆分出来,放到不同的主机服务器上,然后主机之间通过网络连起来,这样数据库就能解决海量数据的存储问题和读写的性能问题, 对于分布式数据库来说,面临的有非常多的挑战,虽然说我刚才讲了它可以解决海量数据的存储问题和读写的性能问题,但是它的复杂度增加了。
这里我们会重点会讲下分布式数据库操作流程, 在我们的分布式数据库里面它是怎么样去处理的,这个是比较复杂,今天我们就来谈谈分布的数据库的事务处理,刚才讲了它解决我们的存储和性能问题,但是它的处理过程是比较复杂的,也就是说我去执行一条SQL语句,它执行的时候,它可能会被分发到各个节点上去同时执行sss。
我们推断未来数据库架构一定是云原生加分布式这样的架构, 分布式数据库支持事务的属性(原子性、一致性、隔离性、持久性), 这里还会涉及到两阶段提交,甚至说其它数据库可能还会涉及到一些其他的一些方式来实现数据的一致性和原子性。
这里我主要讲 TDSQL,TDSQL用的是两阶段提交,比如说用了分布式,我修改数据是很快,但是我后面要去查数据,我要对多个节点的数据进行查询,怎么能保证我这个性能也是ok的,这些都是需要我们去理解。
我们回到我们重点,今天我们讲的是TDSQL的数据库,我们讲TDSQL数据库它是一个分布式数据库,它有哪些特点?
TDSQL是腾讯为金融行业打造的一款国产分布式数据库,它是完全兼容MYSQL和PostgreSQL,为今天我讲的是兼容MYSQL数据库版本的TDSQL, 可以实现性能的线性增长,也就是说我机器不够了,我可以水平的透明的在线上平滑扩容增加机器, 对业务零感知。所有的操作全是线上操作。
而且能够实现强一致性的这样特性,注意。我讲这一款基于MySQL版的,它是基于这个APP场景的去做交易的这样的产品, 它可以用据计算和存储可以分离。 我们在部署当中可以实现同城跨机房,异地跨城机房,像这次郑州水灾 如果说它的数据库在部署没用有两地三中心的架构, 这个数据可能找不回来,所以我们在选型工作数据库的时候一定要考虑它的容灾。
2.分布式事务操作过程解析。
分布数据库最主要的特性是分布式事务,我们先简单来看一下就 TDSQL的核心架构分三块,上层这一块主要是 TDSQL的管理层,以zookeeper为核心,存储整个集群的元数据及服务发现、注册、通知,管理整个集群。 还有一块是计算引擎主要做解析路由以及读写分离等等一些功能。如下图:
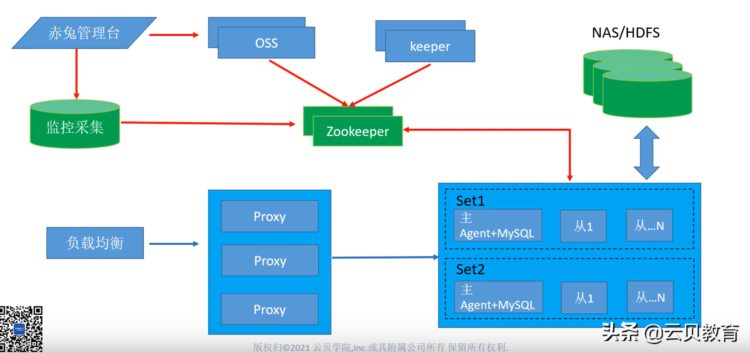
后端还有一块是存储引擎,存储节点这一块主要是以set为主, 一个set大家可以理解就是MySQL里面的一主多从,我可以一主一从,也可以一主两从也可以一主五从,比较灵活,set1、set2代表分布式数据库有两个分片。
今天我要讲的是事务的处理,就是说我应用层通过负载均衡,然后一条SQL发到我们的proxy,然后proxy启动事务,如果是一个分布式的实例,它会启动一个分布式事务,然后进行SQL解析,解析完了之后会把SQL发到各存储节点上执行,存储节点执行完了结果会返回到proxy中,在proxy中对各存储发送过来的结果进行聚合,然后再返回给应用程序。
我们来看一个具体的 TDSQL分布式的一个操作,我刚才讲了我们TDSQ三大核心主组以zookeeper为主的管理节点,proxy计算节点,数据库存储节点。最左边是我的一个客户端程序或者我的应用程序,我要发起一个请求到我们的后端数据库, 客户端不能直接去操作后端数据库存储节点,用set1,set2来表示不同的节点或者不同的分片,我要发起一个SQL操作的时候,那事务肯定会有一个开始,只要发出begin命令, 客户端这边就会在proxy计算节点创建一个gtsn的结构体,也就是说这个操作他会在proxy计算节点分配一块内存同时会产生一个GTID。如下图:
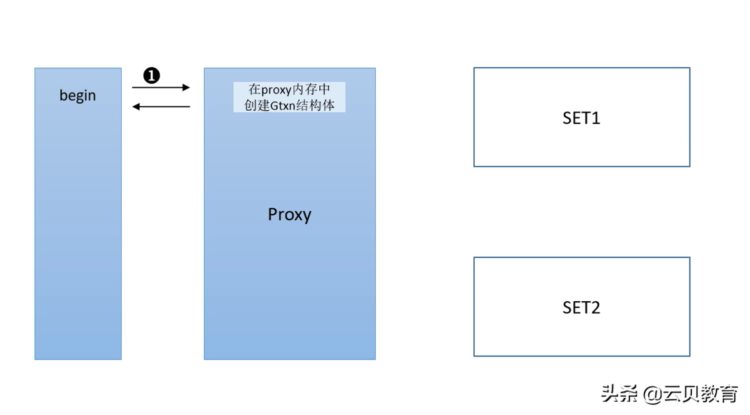
当然注意一下这里的GTD不是MySQL里的GTID,我们这里把它理解为产生一串很长的字符串,如果是一个proxy计算节点的话会成为单点故障,所以它会有一个proxy的编号,然后在proxy后面会产生一个随机的序号,因为我们的全部数据库,我执行的事务会非常大,有可能几十万个事务。多个proxy,随机号后面有一个序列号这样的,同时我们要把我的刚才讲的 gtid要放到一个数据库的表里面
因为我们说分布数据库它整个操作过程比较复杂, 一旦我中间如果出问题了,我要找到是哪个事务,所以在 GTID标识符里面,我们还要放一个随机的 set的编号,因为一旦它产生完之后,它就会把 GTID这个值后面要放到某一个set下面的一个数据库里面去,所以第一步在我们客户端这边发起一个事务begin,然后在proxy里面找一块内存,生成一个GTID,同时返回我们的客户端已经创建完了,然后我们所有的操作都以 GTID为主线。
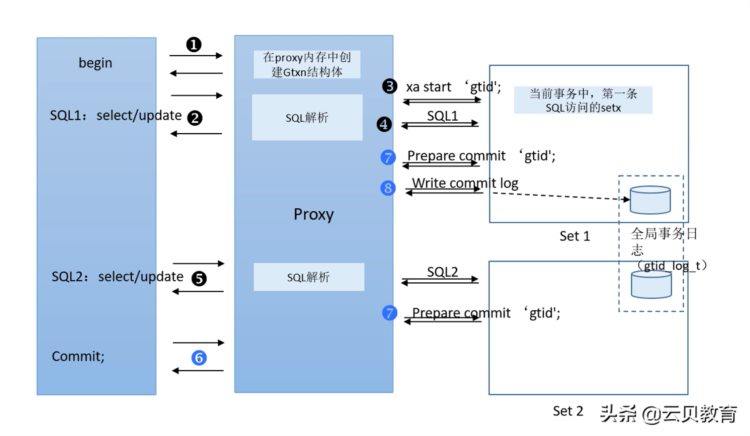
这个时候我拿到了内存,已经拿到了GTID号之后,客户端就可以发起SQL语句,可以发起 SELECT,DML语句到我们的proxy上面去,拿到 SQL,它要看一下 这条SQL是不是分布式的,默认拿SQL的时候,他是以单机版的SQL处理,因为分布式消耗的资源比较多,所以他在解析 SQL的时候,要判断一下 SQL操作的是不是分布式的,如果说是分布式,我们可以看下这个表的分片,这个时候就会去读路由信息,看看 SQL执行的到底是哪几个分片,或者说要执行几个分片,他要判断。
proxy确定是哪个分片之后,它会把 SQL发送到对应的分片上,发送过去的时候,要启动一个 XA的start GTID,注意GTID就是说刚才我们第一步客户端begin的时候产生 gtid,它会存在一个随机的 set上,会根据我们的SQL语句找到对应的set,然后set拿到语句之后,它就会去执行这样一个SQL语句。存储节点上执行完SQL结果,会返回到proxy计算节点。再把结果返回给我们的客户端执行成功。
执行成功之后,接下来我们进行提交。我们发出commit的命令的时候,这个时候他就会执行两阶段提交,第一阶段就会做有prepare commit,其实prepare commit这一步操作还是有点复杂了,MySQL的内部接口一个是xa的prepare,一个是xa的commit, xa prepare主要是他要把 xa start执行完SQL产生的二进制日志要写到本地。同时主库的二进制日志要发送给从库,然后重复要返回一个ack,然后我们要再把执行的成功返回给我们proxy,接收到各个set成功了,这个时候他就会发起第7步。
因为大家注意第7步第二个set节点,第7步这个过程就是相当于把操作的二进制日志写到主库,主库binlog日志再发送到从库,从库返回一个ack,这个过程还是比较长的。第7步已经把二进制日志写进磁盘了,但是对用户来说提交还是不可见的,到第8步的时候,这个proxy都接收到各个节点提交完成,这个时候他要再向各个节点发一个提交完成标识。
第8步完成了之后,我的数据才可见。
这里注意的一点就是,在做第7步的时候,如果完成了,我们会把我们的第一步所产生的 gtxn和gtid这个值会随机找某个set上面的数据库去写,到放到表里防止第7步某个节点提交失败了,可以拿gtid做回滚。
3.为什么选择二阶段提交?
首先我们看下图:
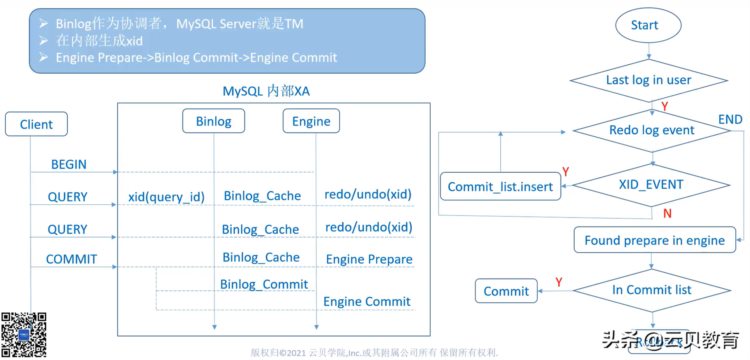
我们说,为什么会选择两阶段去做这个,TDSQL是金融级数据库解决方案,存储节点用了MySQL, MySQL的两阶段提交有外部提交,那MySQL内部两阶段提交是怎么做,它以binlog二进制日志作为协调者。由于MySQL多引擎的架构,我们要保证不同引擎之间的原则性, 我们一定要有一个协调者来协调,万一中间有问题了,我要保证它的数据要一致性,binlog二进制日志作为协调者,就是说我们可以看到在内部执行的时候,他在做xa prepare的时候,只用了引擎(engine)层的prepare,因为它是一个协调者不需要在binlog二进制日志提交的时候,只要引擎(engine)提交,我要协调的引擎和我们binlog二进制日志之间的一个桥梁关联就是有它内部的一个XID,就是事务ID来关联我们的binlog二进制日志和引擎。
如果MySQL说挂了,比如说我最后一个SQL执行一半的时候,突然间挂掉了,怎么来恢复它?只要找到最后一个binlog二进制日志位置,在二进制日志之xid是关联binlog和引擎(engine),首先它会做实例恢复, 拿binlog二进制日志到XID去找内部的提交列表,如果说我 xid在我的提交表表中可以找到,我再执行一遍就可以提交了。如果说在我的提交列表里面没有xid,我就根据binlog二进制日志中的 xid进行一个回滚,它内部是这么实现的。

MySQL 5.6版不适用分布式数据库,分布式数据库稳定在MySQL 5.7.17及以上的版本,其实MySQL 5.7的版本本身也是有些问题的。
MySQL 提交内部有两个接口,一个是xa prepare接口,一个是xa commit接口,这两个结果在内部是持久化的。
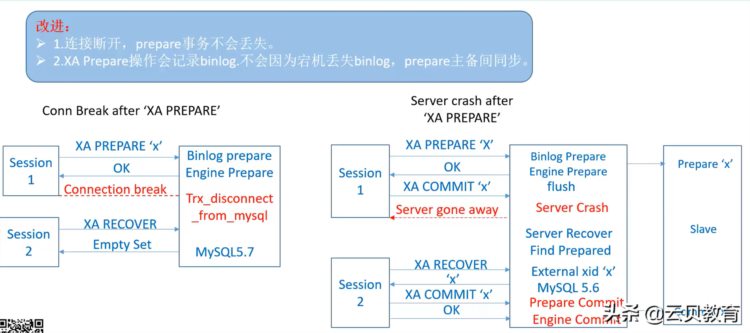
看提交流程它先 binlog日志作为xa prepare,binlog是不能回滚。大家想一下,如果binlog日志写进磁盘之后,这个时候我再去写引擎层的时候,数据库挂了,数据可能就不一致,MySQL5.7是有这么个问题,这个问题我们对它进行改进先做引擎层的xa prepare,再做binlog的xa prepare。
第二个就是MySQL 5.7在xa prepared的时候,虽然可以持久化binlog二进制日志,引擎层日志, 当服务器crash之后,它不会刷到磁盘还是会丢日志的,所以我们做了改进,就是让数据不能丢失。
总结,在没有改进之前,我们在xa prepare的时候不能马上刷数据到磁盘,会丢数据,xa prepare先写binlog日志,主从复制binlog二进制日志写到从库,这当服务crash,binlog二进制日志不能回滚的,数据不一致,所以这个地方就会有问题。
4. 分布式事务全局一致性读
MySQL里面的事务的隔离级别,一般用RC(提交后的读),当然有的使用RR(重复读)做备份?
我们来看这样一个场景如下图:

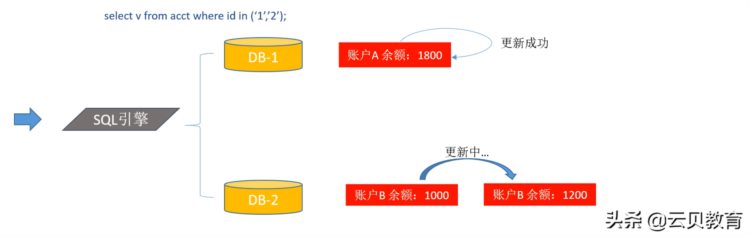
分布式事务的读是怎么实现的,你比如说我现在有两个节点, A节点和B节点,比如A节点账户id=1有2000块钱 ,B节点账户id=2中有1000块钱?
这个时候比如说我的id=1账户给id=2账户进行一个转账操作,比如说我账户id=1要转200块钱给账户id=2,那也就是说我A节点账户id=1上面减去200,那就是1800。
同时我在B节点账户id=2上面加上200。
这个时候分别去执行这两个的操作,在两个不同的节点上作为一个事务,这个时候我发起一个commit的命令会启动两阶段提交,在节点A上面会起一个xa prepare,这个时候就会把上面的二进制日志持久化操作主库,主库发送binlog到备库,备库再返回ack,同时节点B也会这么操作,因为是两个不同的节点, 他们网络服务器都是不同的,有可能中间会有一点延迟,比如说第一节点提交的比较快,这个时候马上提交掉了,我们刚才讲了提交分为两部分,一个是XA prepare,一个是XA commit。
假设说节点B,提交要慢一点,T6这个时间点刚好有一个用户上来查数据,查 ID=1,ID=2的数据,这个数据直接根据分配规则,ID=1在节点A执行,ID=2在节点B执行,是执行分布式事务。
大家看想一下,转账我们要保证两个账户的总额是一样的,比如说两个账户的总额是2000+1000是3000块钱。账户ID=1 ,2000减掉200,提交后账户是1800,账户ID=2,1000加上200,这个时候我还没提交,因为我这里没有提交,产生binlog日志写进去,没提交是不可见的,看到账户ID=2金额还是原来1000,,看到两个节点的数据,一个是1800,一个是1000,总共是2800,那就少了200块钱,ID=1账户钱少了,那数据就不一致了,我们如果来保障数据的一致性,
但是大家想一下,因为我是分布式数据,我们说分布式数据库它的核心可能除了用CAP/BASE,可能实现最终一致性,比如说这个场景,ID=2转账的时候1000加上200的时候比较慢一点,没提交,用户进来查账户余额,没提交可见了,那就有问题了。
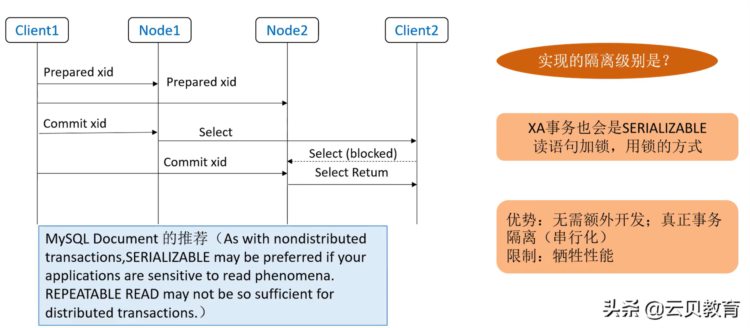
我们想想这种场景我们怎么来保障数据完全是一致的,我们用什么样的方法来实现?有很多的各种各样厂商的分布数据库,我们看一下通用的技术有哪些来解决全局一致性读的问题?在MySQL提出的方案是什么?利用串行事务的隔离级别来实现数据全局一致性读。如果你用串行事务确实可以解决我们读的一致性,而且也不需要额外的增加开发代码或其他的一些。但是这里有个非常重要的问题,就是现在牺牲了性能,也就是说我所有select操作,都要被阻塞,串行事务是我必须要保证前面一个操作完了之后我才能操作,所以用这种方案虽然可以解决全局一致性,但是事务的隔离级别是串行,所有操作都会被阻塞。
所以虽然说这也是个解决方案,但是在我们生产上可能是不现实的,所以不可能用这种方案这种方案。
我们再来看方案啊用 GTM的方案,比如说这个是 postgres- XC它是用这样一个机制来实现这种GTM,就是说GTM这个主机它能提供一个全局的ID号,提供一个GTID,同时还提供了一个时间戳的概念,叫全局快照,也就是说我这个APP这边我请求一个SQL过来之后,到协调器,协调器要做SQL解析,在执行SQL解析的时候,申请协调器要去请求 GTM拿一个全局ID号,因为整个操作事务都是以全局id号为准,同时他其实还拿一个timestamp,在整个SQL操作当中都带有时间戳,保证我的所有的操作是按照这个时间出来。
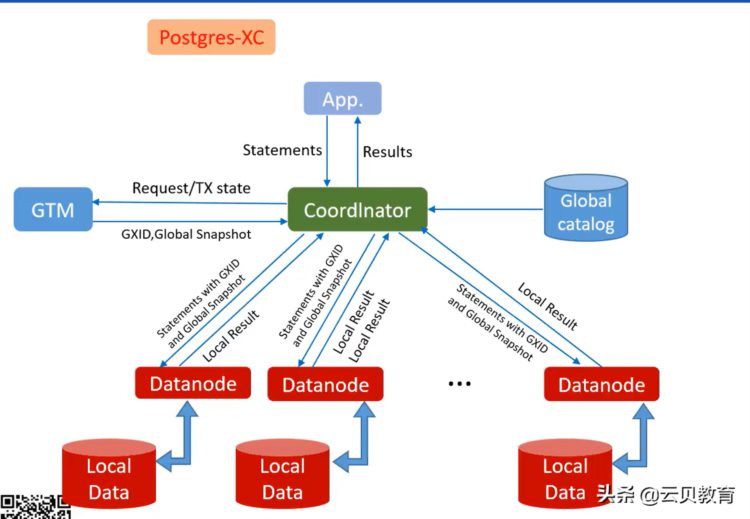
提交的时候, 拿到时间,然后把时间写到磁盘,在分布式数据库去做SELECT读操作,会拿GTM时间,如果说读的时间大于磁盘里看到的提交时间,就可以把它读出来,否则如果读的时间小于磁盘里提交的时间,数据不可见就不能读了,通过时间大小的对比,当然这个里面它就能实现整个集群的 MVCC。MySQL或者 postgresql都是用 mvcc来解决一次性读。GTM这种方案 TDSQL for PG版本,就是用这样的技术来实现的分布式的,这是一种比较通用的方案,它比我们的MySQL提供的行串行性能上肯定要好很多。但是它有一定的局限,就是说是因为 GTM是一个单机的,也就是它可以做一主多从,但主库是不能拆分的。如下图
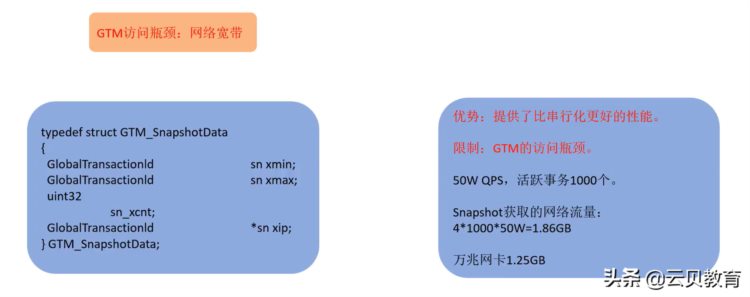
如果说我数据量非常大的时候,它会成为一个单点,因为它是单台的一主多从的,比如举个例子,这个产品就50万的qps活跃事务1000个的话,我们获取的网络流量可能会达到1.86GB,我们的万兆网卡1.25GB,所以可能你量特别大的时候,GTM可能会成为一个瓶颈,一般来说是没什么问题。
还有一种方案就是Google的一个解决方案叫全局时间戳,