编辑导语:相信很多人都听说过用户体验走查,但你真的明白其中的内涵吗?这篇文章作者详细介绍了体验走查之——启发式评估的相关内容,感兴趣的小伙伴一起看看吧。

今天,要讲的内容是用户体验走查(User experience evaluation)。其中重点是:启发式评估的相关内容。
首先明确一个前提:体验走查不是考核。
不要简单的挑界面上物理层的问题(颜色、字号、大小是否统一),这些只是基础一致性问题,还要透过产品功能流程考量是否符合用户行为,它们之间的映射关系是否合理,以及产品使用完成给用户带来的情绪变化,是否是正向的、积极的,是否符合用户的认知。
体验走查实际价值不是发现问题,而是改进问题,从而通过重新设计影响用户体验的因素,提升体验。
体验走查,是每个设计师的日常工作:
设计迭代前,通过体验走查,发现现有产品的体验问题;设计进行中,通过体验走查,审视当前设计方案存在的体验问题;设计开发时,通过体验走查,审视研发还原时存在的体验问题;设计上线后,通过体验走查,发现真实环境中存在的体验问题。
这是常见的几种体验评测方法,我们今天重点讲的是,启发式评估在日常项目中如何运用。

简单说一下它的优缺点:
这个方法相对其他用体验评测方法比较快捷简便。它能够提供有关网页可用性的快速概览,并凸显出可能影响用户体验的一些主要问题;
启发式评估在所提供价值和所需资源方面来说是比较高效的。相比其他的用户体验评估方法(例如问卷调研、用户访谈等)成本更低;
由于启发式评估不涉及用户测试和用户行为分析,所以缺乏“证据”,有时候可能显得比较主观(当然也有些改进型的启发式评估,例如协作式、全景式,这些都有适应的场景和团队,我们暂不细谈);
评估前需要简单准备和培训,但是成本低。
一、什么是启发式评估?

启发式评估法(Heuristic Evaluation)是一种用来评定系统(产品)可用性的方法。使用一套相对简单、通用、有启发性的可用性规则进行可用性评估。
最早由Nielsen和Moclich(莫里奇)90年代提出的一种由专家完成的产品可用性评估⽅法,由多位评估者对照一些可用性准则和依据自己的经验来对用户界面的可用性进行独立的评估,启发式评估的目的不仅是找出系统中潜在的可⽤性问题,更是为了改进问题。
有时侯产品的可用性不能够完全依赖于没有设计知识和经验的用户来实现。而且限于隐私、经验等问题,用户的真实想法并不一定能够完整的传达出来。因此通过设计专家(交互)对产品/原型评估,通过丰富的设计经验来发掘问题并进行有效规避。
二、启发式的主要特征
包含以下主要特征:

启发式评估的其他特征(优点):
快速/划算:使用已拥有的内部团队资源来管理评估;
灵活:在设计过程的任何阶段都可以进行评测,评估线框图、原型、线上产品——或以上所有;
详尽:可以全面扫描产品当前的UX设计;
严重性评级:组织可用性问题,并根据问题的严重程度解决它们;
可用性原则:遵循一组启发式准则可以识别特定用户流程中的问题;
兼容:可以同时结合其他可用性测试方法。
三、什么情况下使用启发式评估?
启发式评估并不限于某个特定的时间段或产品阶段,在任何需要交互专家来评估和验证方案的地方,都可以使用。
甚至你可以理解为,设计团队内部讨论某个方案或者某个交互细节,这时候找来设计主管给出指导,这也是一种形式的启发式评估。
启发式评估可以发生在原型测试阶段,按照正常的设计流程,原型阶段正是验证想法以及测试可用性的阶段,在此时发现可用性问题并进行纠正的成本最低,因为产品尚未开发,没有投入太多资源。
对于已经上线的产品仍然可以进行启发式评估,甚至已上线产品更接近真实产品,因此结合用户的反馈,更容易找出最终的可用性问题。只是修改成本变得略高一些。
补充:一些大型复杂系统项目或重要变现业务需要严谨的、基于数据实验的用户体验流程。
然而,很多规模较小的快速跟进项目通常要求更快、成本更低的评估方法(与基于用研和实验评估相比),很多时候我们希望能够以较低的代价实现较大的效果,而启发式评估就是典型代表。我们将这些评估方法称为“经济评估法”。原因是它们更快速、更节约成本。
要让全员参与到体验走查中来,我们必须为全员提供一个简单、易懂、可信赖的体验走查参考标准。方便全员日常和专项走查时,能够以此为参照,正确、全面的发现并表述体验问题。
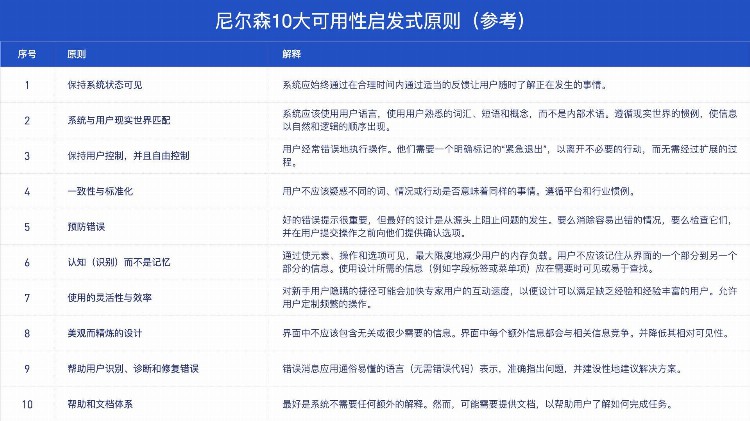
而尼尔森10大可用性原则一定是我们要参考的经典设计准则。
以下是对尼尔森10大可用性原则的重新梳理。它们是有关交互设计的非正式准则、经验法则或通用方针。
这个时候,有的同学会质疑?尼尔森10大可用性原则都过去二十多年了,还适用于当下的产品设计吗?
先说一下,我的感受存在几个阶段的变化:
初识尼尔森10大可用性原则,哇!这么精炼的设计准则,这不就是设计方法论吗?
而做了几年设计之后,更多大厂开始玩起了数据分析,有部分人质疑槽尼尔森那一套东西东西过时了,当然,我也曾这样觉得…
再识尼尔森10大可用性原则,今年有机会深入的再次研究了10大原则,并用我蹩脚的英语逐个单词亲自翻译了一遍。
深刻的发现,市面上各类解读文章翻译的太不准确了,而且最初10大原则适用的是Web端的产品设计,但是各类文章偏偏爱拿移动端去做例子…
仔细研究发现,尼尔森对于这些准则的抽象很精炼,与其说是设计通用准则,更多是关乎用户产品使用过程中的心理变化注意事项。
因此,我认为它并不过时,特别在B 端的工具型产品,依然是很高级、精炼的设计通用准则。
以下是尼尔森本人笔记中回顾:
Jakob的笔记:
我最初于1990年与Rolf Molich合作开发了启发式评估的启发式方法[Molich和Nielsen,1990年;Nielsen和Molich,1990年]。四年后,我根据对249个可用性问题的因子分析[尼尔森1994a]完善了启发式方法,以得出一套具有最大解释力的启发式方法,从而产生了这套经修订的启发式方法[尼尔森1994年b]。
2020年,我们更新了这篇文章,添加了更多解释、示例和相关链接。虽然我们略微完善了定义的语言,但自1994年以来,10种启发式本身仍然相关且保持不变。当一些事情已经存在了26年时,它也可能适用于下一代用户界面。
当然毕竟过去20多年,放眼当下产品设计,根据评测项目不同,是允许由团队对评估原则进行调整和修改;而评估原则的制定是核心难点,建议通过团队协作的方式制定,并定期补充和改进。更多详细的“UE体验走查问题分类及归因”可参考,另外一个文档表格。公众号回复“UE体验走查问题分类及归因”获取。
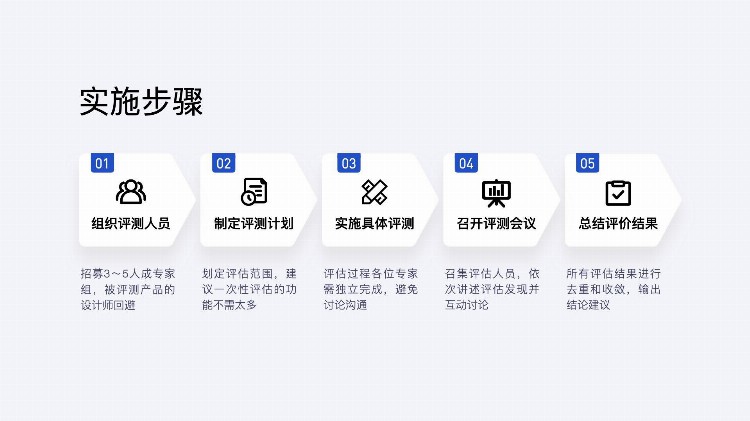
说了这么多,我们讲一下启发式评估的实施流程
启发式评估的整体流程主要包含:组织评测人员、制定评测计划、实施具体评测、召开评测会议、总结评价结果5个部分。
评测人员数量确定
按照尼尔森2000年的实验,一个人评估大约能发现35%的问题,经过公式计算,大概5人就可以发现:50%-95%问题,其平均值为85%,余下20%,通常也是一些重要程度不是那么靠前的问题。
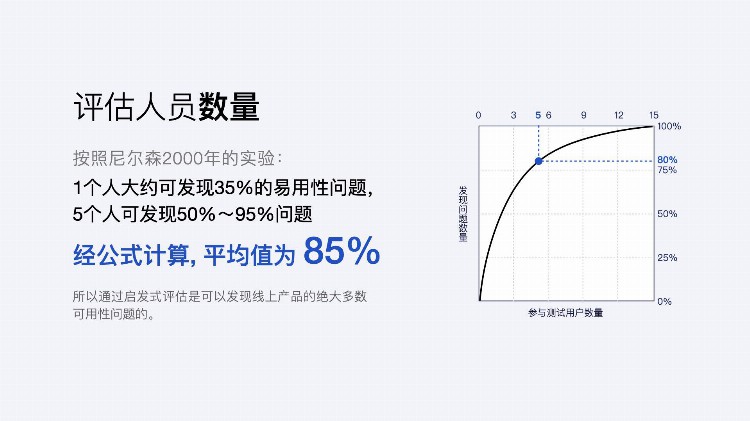
这只是个参考,我认为人数不是重点,重点是事情我们要去做,持续走查缺陷并推动解决,再好的评测方法也不是一次就可以解决所有问题的。
除此之外,还有一些评测过程中需要注意的要点,也是我们要注意的。

同时,根据缺陷对系统可用性所造成的影响,把可用性问题按照其严重性分为4个等级。这是对于发现问题严重性的定义描述,需要设计师在评测前学习掌握,因为个人差异对于问题严重程度的理解不同,我们需要统一标准。

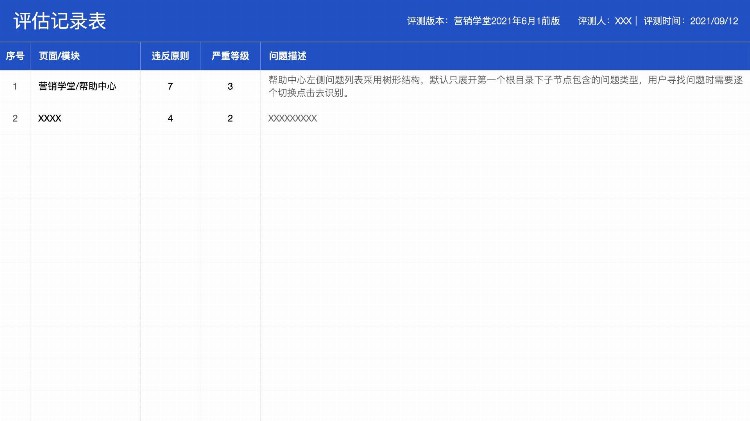
以下是具体页面评测格式示例:
可用性缺陷包含两个方面和四个因素:缺陷的位置及标识;问题及依据。

一个可用性缺陷就是用户界面中特定位置的某个特特征或设施,要通过某个特点问题或困难来加以描述,还要根据某些原理或依据说清楚为什么它是一个可用性问题。
需要注意的是:我们的评测不只是提问题,还有考虑问题的严重性(紧急度),所以我们又做了问题严重性的等级划分,从一般问题到严重问题划分为4个等级。
另外一点是:我们不只是在挑错,描述问题的同时,我们还要分析原因,并尽量提出合理化建议。这样客户看到的分析才是有理有据,不仅发现了问题,还有解决思路。
四、评估问题汇总
在整体功能流程我们走完,要做问题的整理汇总,填写体验问题记录表。这样便于客户查看,也便于我们最后做汇总整理。而且,所有问题的类型、严重性、数量都会有编号,这样我们整理时,统计编号就好了,整体效率会更高。

五、收集了一堆问题之后的处理
通过小组会议讨论,把相同/相近的问题统一,可优化的问题保留下来,不是体验或可用性的问题的去掉,然后整理到一起。这些就是评测范围内存在的大大小小、各式各样的问题了。
可视化整理,便于直观感知:
首先,对问题记录进行归类,以模块横向对比或流程区分。例如:把首页/课程中心等频道页做为模块用图表形式展示问题数量分布,可视化对比各模块问题数量及严重程度分布情况,一目了然。
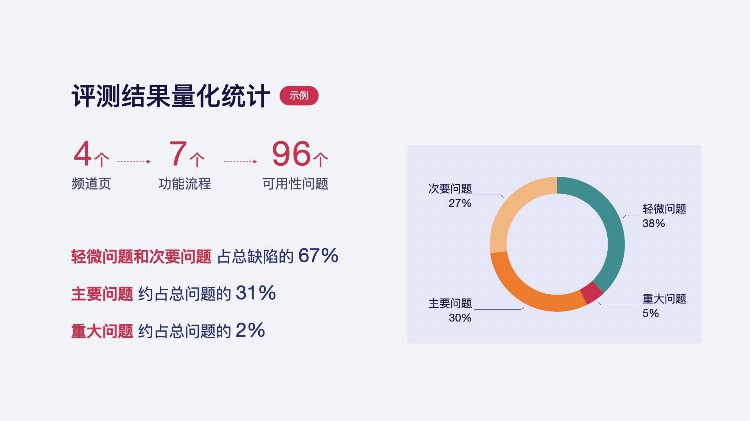
体验评测结果量化:问题数量/问题严重等级
看到问题数量,大家肯定吓一跳,但这就是启发式评估的特点,也是存在的问题:容易查出的问题太多了。因为基于多位成员的评测,及自身经验的不同,在统一评价标准下虽然已经避免一部分主观因素,但是还会存在发现大量问题的情况。
不过这并不要紧,因为即便如此,用户实际中的大半问题已经被我们预测出来了,剩余的问题也不能说没有意义。其中仍然代表广泛用户的心声。
当然,最后我们肯定话锁定主要问题进行解决,以及确定问题解决的排期和优先级。
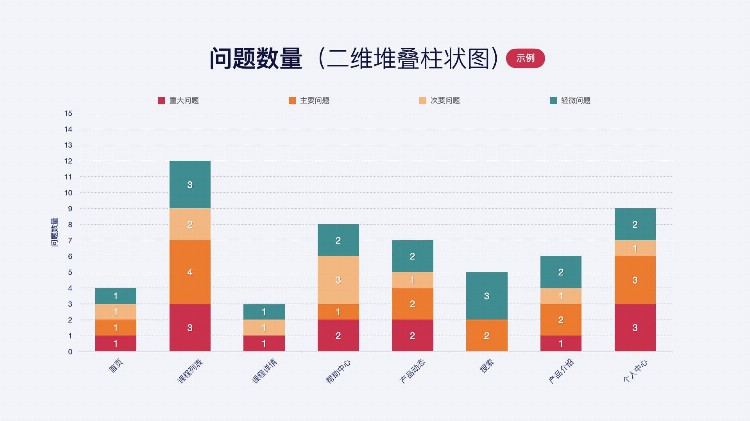
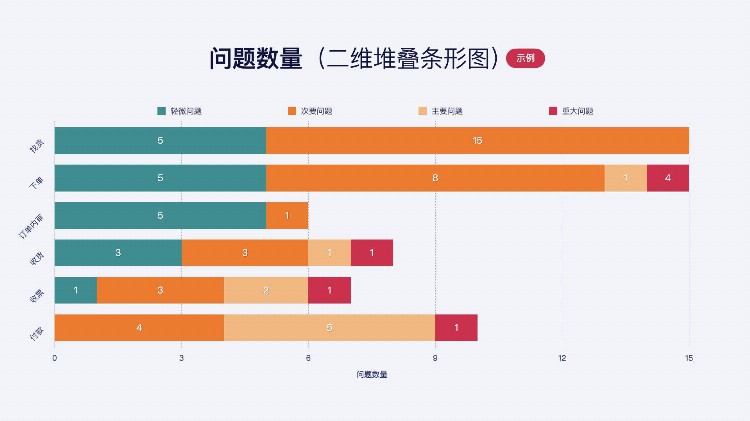
以B2B电商的下单流程为例:
宏观展示,各模块问题严重性分布,主要在哪些模块中,任务流程前后问题出现的线性关系。
堆叠面积图和基本面积图一样,唯一的区别就是图上每一个数据集的起点不同,起点是基于前一个数据集的,用于显示每个数值所占大小随时间或类别变化的趋势线,展示的是部分与整体的关系。
体验走查完成并不代表结束,如何推进后续优化方案才是重头戏
首先需要PM及研发团队的认可走查结果,这涉及信度问题,在方法概述中,已提到。
启发式评估天然存在精度不高的缺陷(受评测人员经验、评测方向、人数等多方面因素影响),所以我们在信度上只能相对的,以通用准则统一评测标准;以商业B端常见度量指标为评测方向、以竞品相似功能的良好体验为横向佐证。

发现一个可用性缺陷并不意味着必须处理它。至于纠正还是暂时搁置所发现的缺陷,这是一个技术性的管理问题,取决于缺陷的严重程度、纠正缺陷所需的费用及现有资源的多少等多方面因素。
体验走查的宗旨始终是:即使在发现缺陷之后决定推迟纠正缺陷或忽略这些缺陷,但知道问题出在何处总比不知道好。

六、总结
那些对产品有较大影响、极为复杂的可用性问题,估算其资源消耗可能比较困难,但对其他的可用性问题改进消耗的人力和工时还是可以粗略估算出来的。
归根结蒂,这是一个管理问题,即根据受影响范围、修改问题所需的资源、现有资源情况等因素,对是否以及何时着手解决已发现的可用性问题做出相应的决定。
经常有这样的情况,有些问题一直拖到后期才得以解决,有些则可以完全忽略。因此,这样的决策非常重要,是靠理性而不是随便做出来的。
发现问题并不意味着必须要改正这些问题,但是了解一下所有存在的问题总比忽视不管要好一些。
当体验问题收集上来后,根据体验问题评估标准,对其进行分级,并按照问题严重级别,分步推进:所有严重/致命的体验问题,直接转化为需求,提到项目侧优先解决。
一般和轻微问题,则由设计师以功能模块为单位,按照功能的重要性和问题的多少进行分类:(a)对于问题比较多的模块,设计师先设计解决方案,再推动到项目侧解决;(b) 对于问题比较少的模块,则等到日常需求迭代时,把遗留的体验问题纳入一起优化。通过这样三步走的方式,逐步推进所有体验问题的解决。
作者:UX老王;公众号:体验为王
原文链接:https://mp.weixin.qq.com/s/KyIXU795hD99Xd5Qa7whMg
本文由 @体验为王 授权发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。